
- 0
- 0
- 1
分享
- 大白话解释 Facebook Oculus团队的手势追踪系统——MegaTrack
-
2020-12-09
本文转载自微信公众号:AIRX
一、前言
本文是对Facebook Oculus发布的一篇VR方向(手势追踪)论文的解读。Oculus是一家做VR的公司,2014年被FaceBook收购了,本次参考的论文就是FaceBook Oculus团队的最新论文。论文2020年7月发表于SIGGRAPH。
因为最终是要给大家讲明白这个手势追踪是怎么实现的,所以我尽量不出现数学公式,尽量使用中文。
【补充】SIGGRAPH是什么?:Special Interest Group for Computer GRAPHICS,计算机图形图像特别兴趣小组,成立于1967年,可以看作一个论坛或者是会议,内容主打电脑绘图和动画制作。绝大部分图像相关厂商和游戏制作者都会每年在这个会议上发布自己的作品和科研成果。因此,SIGGRAPH在图形图像技术,计算机软硬件以及CG等方面都有着相当的影响力。
二、论文分析
1、这篇论文讲的啥?
现在市面上的VR游戏机,都需要手柄一类的操作杆来获取玩家手部动作和实时坐标,如下图:

而本篇论文中所提到的手势追踪,则不要手柄操纵杆之类的外设。实现效果如下图:
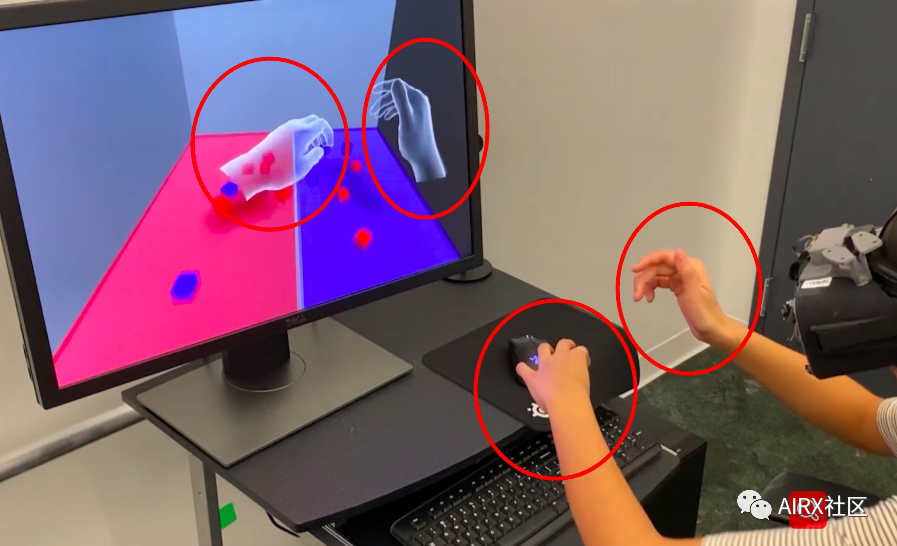
说白了,他这篇论文讲的就是,他怎么实现的第二张图——手势追踪。而他这个手势追踪系统的名称,叫做MegaTrack。
而我接下来的任务就是以平易近人的科普方式,给大家讲解他们团队的手势追踪系统是如何实现的。
2、直接传感器->间接传感器
为了脱离操纵杆,最开始人们的解决方案是制作一双充满电容手套,玩家戴上手套之后,系统就可以完美的掌握手势的每一个细节,但这样和直接握操纵杆没有本质区别,二者都属于在手部直接安装传感器。这篇论文的第一个特点:就是不安装直接传感器,通过摄像头观察手部姿势+深度学习来达成间接传感器的作用。
【补充】两种间接传感器的对比:首先,谷歌也有一个类似的手势追踪系统——MediaPipe Hand。
- MediaPipe Hand采用的是一个摄像头(非3D摄像头/深度摄像头),虽然一个摄像头无法展示场景的深度,但是谷歌采用了2.5D技术去近似模拟3D。
- 2.5D是啥?在摄像头输入图像中,在大部分的情况下将手腕处或是手掌中心会被设为相对深度的基准点,也就是这个位置的深度视为零。这种表示相对深度的方法被统称为2.5D表示法。
- 当然,只有一个固定的摄像头是肯定无法提取深度信息的,所以团队使用神经网络来进行训练,他们是用深度相机为每一帧图像打标签(深度信息),之后测试集使用的是普通相机。
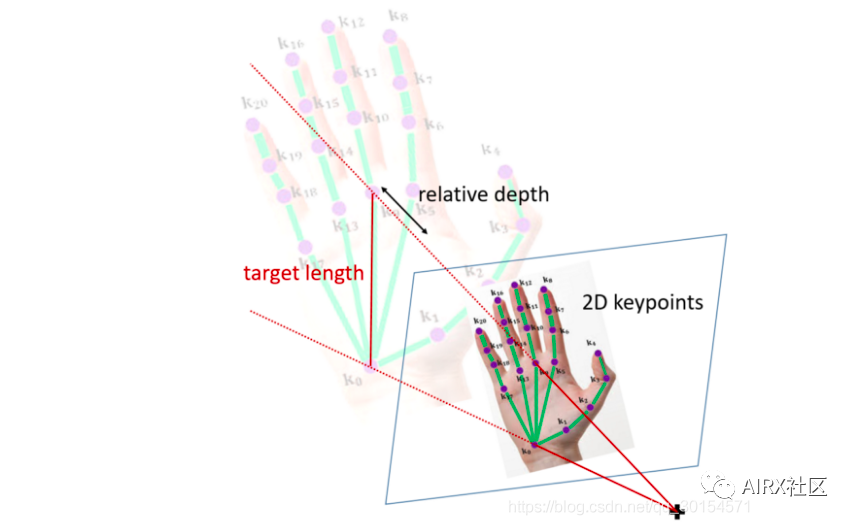
有了深度的基准点,接下来的问题变成2.5D表示法要怎么近似真实3D位置。现在我们有:
- 各个点在影像上的2D位置;
- 各个关键点的相对深度。
- 这时候只要再假设手骨长度,将2D的预测与相对深度以几何投影方式投到3D空间,并放置在手骨长度恰好等于假设值的3D位置上,这样就完成了3D手姿态的近似。
2.5D 映射为 3D 过程如下图:
再说本文的主角MegaTrack:
MegaTrack采用了四个灰度摄像头用来感知手部姿态,如下图:

这样,使用者的手至少会落在两颗相机的视野之中,如下图:

由于MegaTrack使用了4个摄像头,所以相比于谷歌的解决方案,具有以下优势:
- 能够更好的解决“遮盖问题”(手被物品遮蔽或自我遮蔽 ,比如说背面拳头事实上,遮蔽是所有基于视觉方法的难题,这点如果不考虑非视觉的输入,就只有增加更多不同视角的相机输入了)
- 在大多数时候他们会使用 multiple cameras with geometric calibration的演算法,只有在极少的位置使用单一相机的演算法。(比如手的位置特别的远离身体,以至于只有一个摄像头能捕捉到手的姿势…)
- 在3D hand pose estimation演算法方面,Oculus除了会采用2D/2.5D hand pose estimation方法外,还可以更进一步地利用多相机的几何校正优势。
- 同时,由于它具有四个摄像头,于是就可以在最初的数据采集中获取一些3D坐标用于辅助最终的手势坐标。
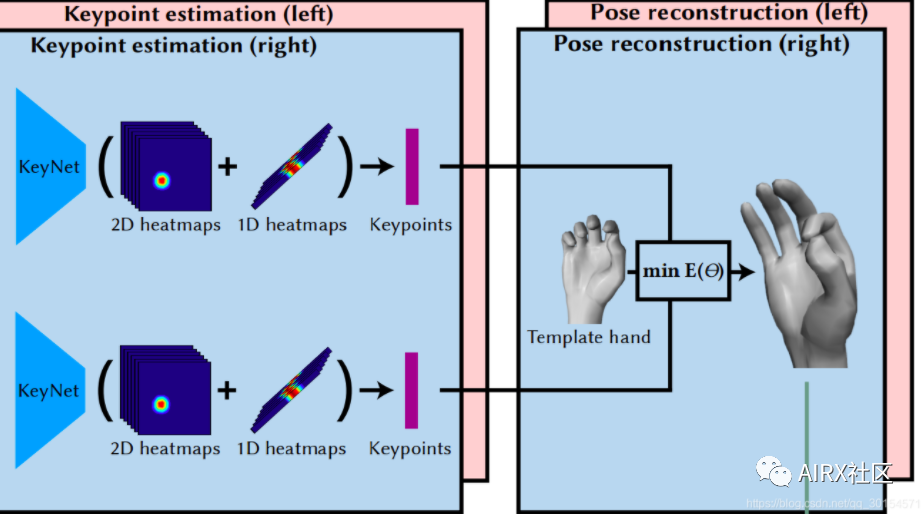
3、实现过程
介绍完了硬件,现在开始介绍实现步骤,可以分为三大步:
- Detection (DetNet)——手部探测网络(自己翻译的…)
- Keypoint Network (KeyNet)——手势关键点生成网络
- Hand Kinematic Model(或者说手势估计)——建立手部动态模型
注:前两步都是通过神经网络来实现的。
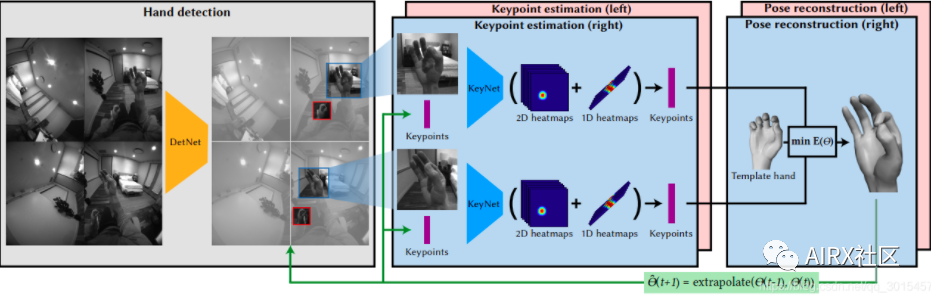
3.1 DetNet(手部探测网络)
- 团队使用了260万张照片来训练DetNet来提取手部图像。
- VR眼镜上的四个摄像头采集影像(VGA格式),每一帧将手部信息裁剪成正方(因为正方形图像方便神经网络计算嘛),输入到下一层。
- DetNet,结合了通过跟踪检测的策略,可以优雅地处理手部在多个摄像机之间的移动。

KeyNet使用了200万张图片来训练网络,来预测手势关键点的2.5D坐标。
- 注意:KeyNet的训练的图片来源,来自该团队实验室的深度相机。
- 当模型已经训练好之后,在VR眼镜中则使用已经训练好的模型+普通摄像头来近似深度摄像头的作用,以节省成本。
在KeyNet层中,首先输入手的影像(已经处理成正方形)和21个用于参考的3D手势点(这21个点来源自上一轮的Hand Kinematic Model,有点循环神经网络那种感觉);随
后通过网络输出21个预测出来的2.5D 手势关键点坐标。
之所以输入来自上一轮的用于参考的3D点,是为了拟合真实数据和模拟数据的误差,也为了解决输入图像手部关键点的抖动问题(个人理解,这一步运用了残差的思想,把我上一轮生成的关键点用来辅助下一轮关键点的预测。毕竟有上一轮的参考点,就可以更重点观察新关键点的特点和分布)。
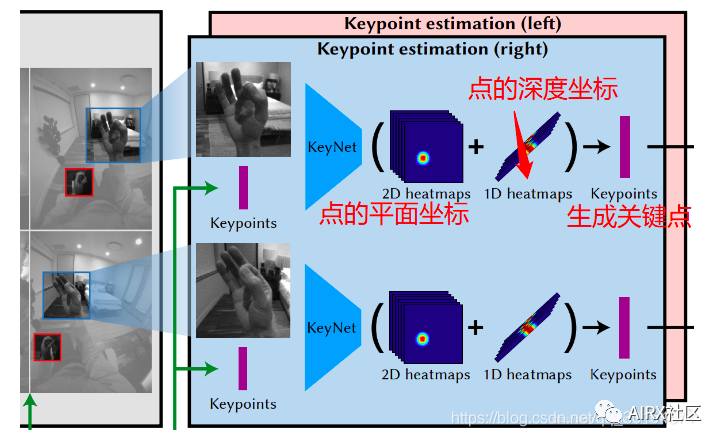
- 值得一提的是,MegaTrack KeyNet的一大特色就是除了影像外还要输入一组参考用的keypoint 3D pose,而这组21个3D pose最大的效果在于稳定模型的预测,在某几帧采集效果不佳的情况下,依然能提供稳定的模型预测。
- 对于MegaTrack系统来说,90%的关键点预测是由上一步输入的3D生成,剩下的10%的关键点的预测是由20帧前的手部姿势生成。(具体又是怎么根据前20帧生成的剩下的10%的点在此先不解释了)
3.3 Hand Kinematic Model(手部动态模型)
这一部分的作用:
- 使用KeyNet输出的2.5D 的手势关键点来最终生成3D手势。
- 另外,一个新的使用者使用VR设备,整个手势追踪会先进入kinematic model scale模块,进行手部姿态的校正。
具体流程:
- 使用一个26 关键点的手部动态模型,通过观测KeyNet预测的2.5D pose,去近似真实的3D 手势。(为什么这突然变成26…我也不知道)
- 其中,手腕6 个关键点,每根手指4个关键点 ,对KeyNet的2.5D pose计算残差,并使用Levenberg-Marquardt方法最佳化。
Levenberg-Marquardt方法,是一个穷举3D空间中手的方法,并从中挑选最符合相机观察(KeyNet输出的2.5D pose) 的那只手,就是这个演算法最终输出的结果。
最佳化时,通过forward kinematic,得到3D空间中的21个3D点 (与KeyNet一样的21个点)。实际上最佳化的residual term有三项:
- 将21个3D点投影回相机空间,与KeyNet预测的2D pose越接近越好;
- 计算21个3D点的relative distance,与KeyNet预测的depth distance越接近越好;
- 与前一个pose越接近越好,即smooth term。
- 首先,在轮流在不同camera上跑DetNet,直到找到使用者的手。
- 再利用这个camera的影像通过KeyNet和Hand Kinematic Model得到第一个3D pose。
- 随后,利用这个3D pose投影到其他camera中找到别的camera中的手。这个方法减少了多次跑DetNet所需的运算资源(相当于告诉DetNet一个手的大致位置,从而不需要让DetNet进行全图搜索)。
- 接下来进入手部追踪模式,每次进行KeyNet的时候,插入上一祯的Hand kinematic model,以推测下一祯手会出现的位置,更进一步的减少运行DetNet的运算需求,稳定手部姿态的运算。
- 运行100帧之后,这个手的scale会被储存下来,直到VR眼镜被放下才会清除。
- 大多数的情况下,只有KeyNet会持续地运行,DetNet只有在丢失手部追踪(比如手突然抽走,再突然出现在另一个位置)的情况下才会被重新启动
- 另外,为了压低运算量,即使同一支手存在于超过两个camera的视角内,MegaTrack还是只会跑其中两只camera。
5、本论文中,MegaTrack的缺点
在双手有复杂交叉的时候,识别会失效

当收的方向并不是以自己的方向为中心时,识别会失败

手和现实物体发生交互式,识别会失败

论文地址:
https://research.fb.com/wp-content/uploads/2020/08/MEgATrack-Monochrome-Egocentric-Articulated-Hand-Tracking-for-Virtual-Reality.pdf

欢迎大家关注我们的B站官方号:AIRX三次方。我们会定期和一些ARVR、AI企业和高校合作直播,分享前沿ARVR、AI、CV、Unity、Unreal技术和教程。

AIRX三次方是面向学生和0-5年经验职场人的新技术学习在线教育平台(专注AR、VR、Unity、Unreal、CV和AI领域)。致力于产出优质新技术教育内容,打造开发者学习服务闭环,关注其职业持续性学习成长。帮助年轻人获得适应未来社会的新技术能力!
欢迎加入AIRX,一个超酷的新兴开发者在线教育与学习服务交流平台。作为国内最早最优质的ARVR、Unity、Unreal、CV、AI开发者学习平台,与全球顶尖大学教授、高校、企业、新媒体艺术家以及AI、CV领域的工程师合作,共同研发优质实用的ARVR、Unity、Unreal、AI课程,在线教育+开发者服务+产业对接平台的业务组合方式服务好开发者、企业用户和高校~扫描下方二维码进群交流(备注:”昵称+学校/公司+研究方向“)

-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文由 “数艺网” 授权数艺网发布,已由本站编辑优化排版。 转载请务必在开头或结尾标注 “作者:XXX | 来源:数艺网”,尊重原创及授权权益。 并附上本页链接: 本站部分图文取自网络,如涉及侵权问题,欢迎通过微信 ID:d-arts-cn 告知。我们会立即核实并及时处理,感谢您的理解与监督。
-

-
苏州
甲方 · 媒体平台
已认证的机构号







