
- 0
- 0
- 0
分享
- AIR学术沙龙第12期 | 罗元:人工智能在多模态电子医疗大数据中的应用
-
原创 2021-11-11
现在我们积累的医疗数据,模态、数据量越来越多,希望大家可以把数据共享,组成大的医疗网络共同合作。
——罗元
活动概况
11月10日上午,第12期AIR学术沙龙在线上如期举行。本期活动荣幸地邀请到了美国西北大学医学院罗元教授为我们做题为《人工智能在多模态电子医疗大数据中的应用》的报告。

主持人刘菁菁教授
本次讲座由清华大学讲席教授、智能产业研究院(AIR)首席研究员、国强教授刘菁菁主持,活动为线上(视频号、哔哩哔哩)的模式,共计约2000人次观看。
讲者介绍

罗元,现任美国西北大学医学院副教授,同时也是西北大学临床和转化医学学院的首席人工智能官(Chief AI Officer)。本科就读于清华大学电子系,之后获得麻省理工学院计算机系博士。研究领域包括机器学习、自然语言处理、时间序列分析和多组学在临床医学中的应用。罗元教授致力于开发并应用图神经网络和非负张量分解等前沿方法来融合多模态医疗数据,进行自动知识抽取以及计算表型的挖掘以辅助医疗决策,以及整合基因变异和表型病变特征从而深入解释致病机理。相关研究发表于Nature Medicine, AJRCCM, AAAI等主流期刊和会议 。
罗元教授现为美国医学信息学会会士(AMIA Fellow),曾获美国医学信息学会2020年度杰出青年科学家奖。
报告内容
临床指南与对照试验
医学在临床实践中会用到各种各样的临床指南作为指导;但是指南内容依据随机对照试验的比重比较少:美国心脏病学会和美国心脏协会发布的指南只有11%的内容依据于试验结果,传染病领域只有14%,对于重症监护领域,只有9%左右的临床指南依照与对照试验结果。

给大家举一个例子,在200多年前,67岁的华盛顿感觉自己喘气困难,并且有喉痛疼的症状,医生给他放了40%的血,然后华盛顿就去世了。可能今天来看医生的操作会让人非常费解,但是200多年前,这样的治疗不是基于严格的数据试验或者是证据,而是基于专家的意见。时至今日,情况依旧不容乐观,但是可以从中看到一点曙光,因为现在可以利用大量的多模态的医疗数据进行分析和试验。
西北医疗数据仓库和eMERGE网络

团队构建了一个覆盖整个大芝加哥地区的西北医疗数据仓库,这个仓库覆盖了11家医院,200多个门诊以及4,000多个医生。包含900万病人的化验结果,各种数据元素加在一起有28亿左右。其中包含结构化数据,以及文本形式的医疗病历。因为不同的医院会用到不同的医疗系统,同一家医院也会更新自己的医疗系统,有专门的团队来负责医疗病历的转化,将它们映射到同一个数据结构。这些数据不仅支持医院的运营,同时也支持医学院的研究员做各种各样的科学研究。

除了和医院的合作,团队还和美国的其他比较大的一些学术医疗机构,合作建立一个电子病历和基因网络(Electronic Medical Records and Genomics Network)。建立这个网络的初衷是对病人不只收集电子医疗病历的数据,还同时收集基因测序的一些信息,有了基因和表型的信息,才能更加精准的对这个病人进行比较有效的靶向治疗。这个网络在地理上、病人族群上、以及临床实践上有着多层次的多样性。
多模态数据的分类

数据包含各种模态,第一类是文本形式的医疗记录,做自然语言处理的同学比较熟悉这类数据;第二类是医疗图像,比如说X ray和CT之类的图像;第三类包括基因组,蛋白质组等组学数据(Omics data);第四类是时序数据,比如说在重症监护室里面观测的病人各种体征数据,不同变量的记录会呈现出不同的频率;最后一类是医疗保险的数据,医疗保险的数据对于电子病历数据可以形成互补。原因在于如果病人换了医院,医院之间的数据一般是不共享的,但是病人的保险只要还是从同一个保险商购买,就可以通过保险数据看到病人之前有什么样的疾病,开了什么样的药。病人的很多模态的数据其实都存在各种各样的互补性。
NLP服务化

大家可以用这些多模态的数据做各种各样的事情,比如说团队一直希望从文本形式的电子医疗病历提取到有用的特征给需要的医疗学者,但是他们可能并没有NLP相关的知识。NLP的流程涉及到断句断词,实体分析以及关系分类,这套流程对于大多数人来说还是非常复杂的,然后也比较费时费力。团队的方法就是把这套流程服务化(NLP as a service),把这些电子病历的实体和关系都提取出来,然后存放到一个统一的数据结构中,虽然不同的医院可能有着不同病历的模板,但是统一的格式便于他们共享数据,可以去研究一些更加复杂,更加罕见的疾病。
医疗语义关系分类

在此pipeline的基础上,可以做很多事情,如说以语义关系的分类为例,治疗手段(treatment)和疾病症状(problem)之间可以形成一些语义关系;一些治疗手段会有效治疗疾病,但有一些会导致一些新的问题,比如说阿莫西林导致腹泻,也有一些治疗会使得情况更加恶化。因为药物包含了各种各样的副作用,临床试验收集到或者是所观测到这些副作用,可能只是其中的一个子集。这个药物在被药监局批准上市后,在经过10年20年的使用当中会观察到各种各样的药物副作用,其中这些观测和记录一方面依赖于病人的自发的汇报,另一方面是制药厂自发的监测。病人的观测可能不准确和严谨。药厂也没有很强的动机来全面汇报自家生产的药物的毒副作用。有了大数据的支持后,大家希望能够通过对电子病历的数据的分析来做这种语义关系的分析。
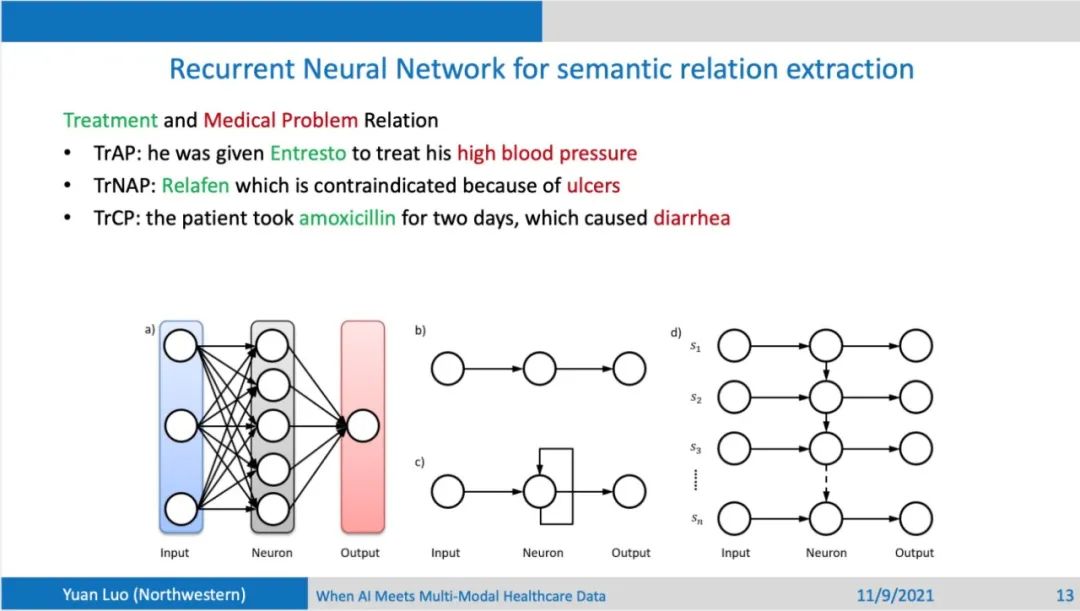
怎么来做这样的一件事情,首先团队想到的是人工神经网络,简单的前向网络结构要求输入长度是固定的,但是在医疗文本中,句子长度是可变的,利用递归神经网络来处理可变长度数据,同时使用LSTM来对信息进行有效的传递和筛选。同时用句子中包含的治疗手段(treatment)和疾病(problem)来把这个句子分成5部分,每个部分都可以用LSTM学一个特征表示(representation),最后汇总这5部分的特征表示来进行关系的分类。
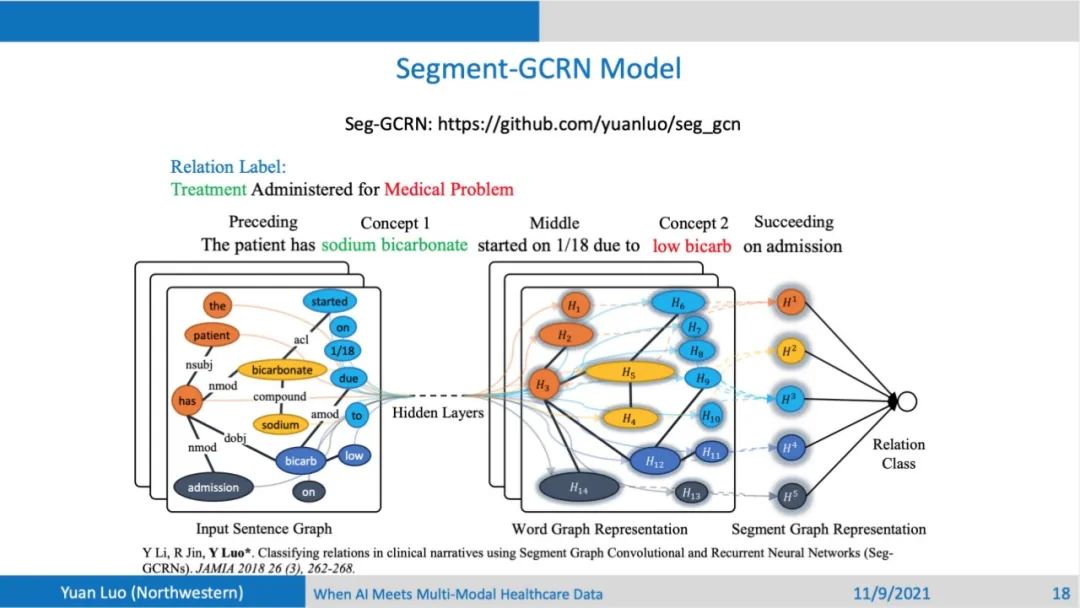
也可以用卷积神经网络(CNN)来作为网络主体结构,卷积可以视为非常简单的一个滑动窗口,对五个部分别进行操作,最后也用汇合5部分特征的方式来进行分类。这种方法可以一定程度上捕获到单词的顺序关系, 不足的之处是不能提取输入的语法关系。英语句子中的单词如果有从句来修饰的话,不同实体的距离会比较远,中间隔了比较多的修饰单词,这种实体之间的long range dependency比较难以捕获,此时可以对句子进行语法分析,分析得到一个Sentence Graph,包含了各种类型实体节点的关系。输入就变成了一个图的结构,此时就可以利用图神经网络来学习特征表示,进行后续的关系分类。可以看到,依次尝试了LSTM, CNN到最后的图卷积网络后,得到的结果是越来越好的,相比于SOTA的方法,也是有明显的提升。
长文本分类

刚才的举例属于短文本的语义理解,去分析同一个句子中的两个concept是怎样的关系。也可以做长文本的语义理解,一个应用是利用文本病历来分析肥胖症与并发症之间的关系。一个肥胖症病人的病历可以同时记录糖尿病,或者心脏衰竭等各种并发疾病。团队提出一种知识引导的卷积神经网络来解决这个问题。除了利用单词之外,还可以利用concept来学习特征表示。concept是比单词更高一级的抽象表示,可以用两个完全不同的词组来表示同一个concept的映射。这种关系可以作为一种知识来引导卷积神经网络进行学习。

另外一个长文本的应用是来做淋巴瘤的分类。现有的分类指南是一直在变化的,每次指南的变化需要许多专家进行长时间的讨论。团队希望从数据之中能够给到专家一些建议。医生在诊断疾病时比较关注细胞和抗原或者抗体之间的关系,单个的关系可能还不足以让医生给出一个确定的结论,但是一组对应了一系列的检测的检测结果的关系,就可以帮助医生给出比较准确的诊断结果。团队要做的事情是用一个张量模型,能够从这个文本当中找出这样一组关系,对应的是一系列的化验结果,这对于医生的诊断可以起到一个提示作用。

也可以利用一些结构化的医疗数据来做风险预测,比如说重症监护室的各种体征检测数据,团队把这些数据离散化,用序列或者是图来表示这些数据的变化趋势。可以想象,病人有可能有多个化验结果,不同化验结果体现了不同的器官异常的表现,一组化验结果可能对应一串异常序列。可以利用这么一组变化趋势,来刻画一个或者多个器官的异常,从而做出这个病人的风险预测,例如死亡率的预测,以及病人再入院风险的预测。
呼吸机资源分配
结构化的数据可以用来来分析和引导一些公共卫生政策的制定。比如疫情期间,医疗资源的分配的不公平的现象。团队做了一个非常简单的实验来分析在现有分配政策下,疫情期间重症监护室里的病人所能够得到的呼吸机的资源是不是公平的。美国各州制定了不同的呼吸机分配政策,初衷都是想让大家能够更公平的得到呼吸机的资源,不受肤色和人种等因素的影响,但是发现这些政策或多或少还是会导致分配不均的现象。

团队研究了四种不同的分类政策。第一种是完全随机;第二种是年轻的病人优先;第三种的分配依据是SOFA,SOFA反映了重症监护室里面病人的严重程度;第四种除了SOFA,还考虑并发症的严重程度以及病人的年龄。团队使用的数据来自于芝加哥的三个大型医院,有2个是三甲医院,另外一个是社区医院体系。研究对象包含这三个医院从20年到21年5月的时候所有重症监护室里面的病人。从这个表格中可以看到,每个病人的各种各样的特征,不同的医院的病人的人种和肤色分布有很大的不同。虽然三家医院都在芝加哥,但是还是有人种分布的多样性,死亡率在不同的医院也有很大的不同。首先看不同年龄的病人得到呼吸机资源的分配情况:随机系统下不同年龄段都一样;年轻人优先情况下年轻人分配的资源也会多;SOFA only的情况下,资源分配对年龄比较均衡;但是在Multi-principal的情况下,年轻人也会得到更多的呼吸机资源分配。

观察不同年龄段下的存活率:完全随机情况下,虽然不同年龄分配的资源是一样的,但是存活率和年龄存在一个高度相关的关系,年龄越小,存活率越高,这种现象在年轻人优先的策略更加明显。然后,观察不同的种族之间在不同策略下的分配资源占比,虽然SOFA 和Multi-principle和年轻人优先的政策在制定时,都没有把种族作为考量的因素,但是从结果上来说,比如说对于SOFA和Multi-principle,Black病人所能得到的呼吸机的资源明显比其他两个种族要少。最终导致的结果就是,Black病人的生存率也比其它两个种族要明显的少。还可以发现,在年轻人优先这一政策下,因为Black病人和Hispanic病人中年轻人占比都比较大,他们反而能够分配到较多的资源,生存率也能得到提升。再来观察SOFA only和Multi-principle下的资源priority score,按照不同种族来划分的分布,可以看到Black病人重症比较多,所以导致他们的分配资源优先级也比较低。因为分配政策在制定时,会或多或少的考虑分配资源给那些比较容易救活的,以求挽救更多的生命。
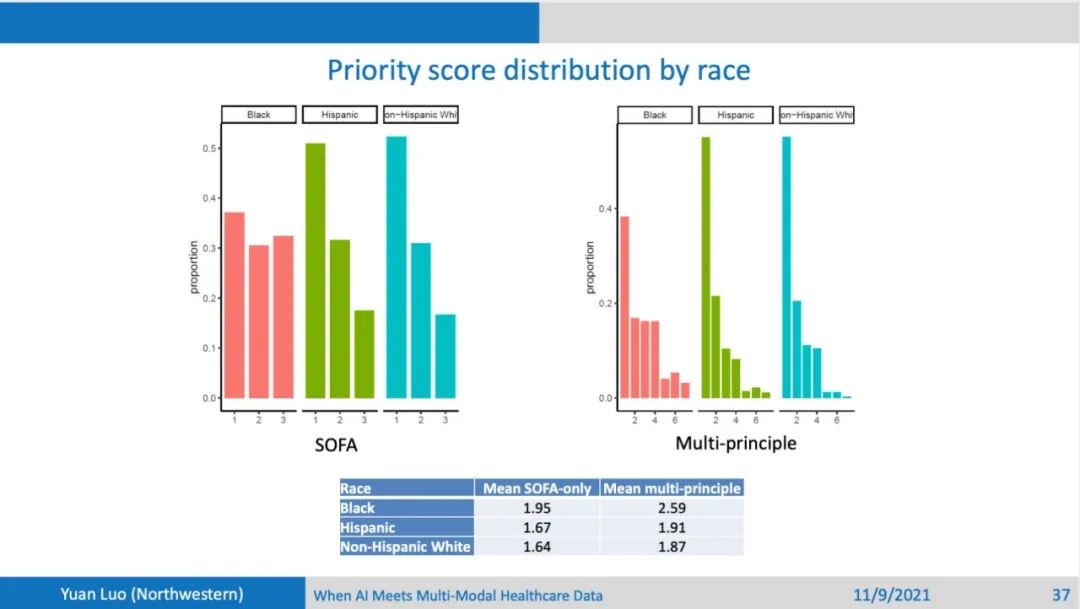
因为不同种族的 priority score的不均衡性,会导致的资源分配甚至是生存率上的不公平性。这个实验可以说明,用一些比较简单技术来对这种回顾性的数据进行分析也可能看出来很多的问题。虽然政策的制定的考量的初衷是避免不公平性,但是还是会有一些潜在的因素导致不公平性。比如对于Black病人他们可能长期处于弱势地位,他们的健康状态相比于平均水平就是要差一些的,在这个看似公平的政策下,可能他们分到了医疗资源就会出乎意料的不公平。结构化的医疗数据对制定政策能起到一定的导向作用,或者能够检验制定的这样一些政策是不是能够达到所期望的初衷。
多组学数据(Omics data)的应用

我们团队也一直在尝试把机器学习的方法从文本数据,延伸到结构化的数据,然后再延伸到多组学数据。这些多模态数据之间,尤其在经过一系列预处理以后,在很多地方都具有相通性。目前也取得了一些成功,比如说把卷积神经网络应用到基因序列上,来进行癌症种类的分类也可以得到一个比较好的结果,训练的分类器可以达到 state of the art的水平。

可以单独使用每一种模态的数据,但是一个更加有意思的尝试是,如何能够结合两种或者是更多模态的数据,把他们结合一起使用,这是否会产生一些单模态数据所达不到效果。在这一个实验当中,团队尝试用一些表型(phenotype)和基因(genotype)测序的数据来对高血压病人进行细分,希望能够对不同表型组的病人进行靶向治疗。高血压虽然名字上看上去好像是一种疾病,但是其实这类病人是一个非常异质化的群体。目前市场上的降压药,基本上只对50%的病人有效。高血压病人具有各自不同的特征,会导致一些通用的降压药对他们根本没有效果。团队希望能够用表型和基因数据来标记出这些不同的特异性。这样有可能就能够更加精准的对他们使用一些靶向的药物,以提升治疗的效果。这是做的其中一个尝试,大家如果想了解更详细的结果,可以去访问这篇文章。
多模态数据来辅助早期筛查自闭症

最后是去年做的实验,这个尝试基本上用上了目前团队所能拿到的各种模态数据。团队尝试去研究自闭症这样一个特殊的人群。大家如果看过《雨人》这部电影,就可能会对达斯丁霍夫曼扮演的自闭症患者的形象记忆犹新。自闭症是一种遗传性疾病,它的发病率虽然目前并不是很高,大概是每六七十个儿童当中会有一例,但是发病率在逐年上升。自闭症还有一个特点就是男女比例为4:1,在婴幼儿时期很早就发病,目前来说自闭症没有没有特效药,能唯一能做的就是尽量早的诊断发现,从而尽快进行干预,使患者在长大以后可以尽量获得独立自主性。但是目前来说对自闭症的病因团队了解的非常少,同时也没有一个有效的生物标记(biomarker)可以作为一个早筛的有效依据。团队想要做的就是看能否从各种模态的医疗数据出发,找到这样一些生物标记,可以在刚出生的婴幼儿或者是在出生之前(母亲怀孕期间)就可以进行自闭症患者筛查,从而尽早的开始治疗。但这个问题非常困难,因为在全外显子组测序(whole exome sequencing)中,每个个体的变异数量可以达到两三万,在这样一个大的变异集合中找到一些和自闭症是高度相关的关键的变异从而指导生物标记的搜索是很有挑战的。
团队所采取的策略可以看做是一种暴力美学,把所有能用的数据模态都放在一块。 第一个数据是大脑各组织结构中RNA表达数据,这个数据刻画了人的大脑从胚胎到成年发育的不同阶段RNA的表达变化。对这类表达数据,团队根据时序进行了一定的筛选,保留在出生前后男女之间有很强的差异性。第二个数据来源是遗传病系谱图。病人群体可以分为两类,一类是所谓的 simplex family,这类家庭当中有一个小孩是患有自闭症,另外一个小孩是没有自闭症的,观察他们差异性的变异就有可能比较准确的找到和自闭症比较相关的一些基因变异。第二类是所谓的 multiplex family,这类家庭当中的多个小孩患有自闭症,对于这样的家庭,可以观察共同的变异,这样的话就能够更精准的找到和自闭症相关的变异点。第三类的数据是likely gene-disrupting的数据,用各种基因模型来对变异进行筛选,保留这种likely gene-disrupting变异点,这样的变异能够造成对病患的实质性的损伤。通过这样几种数据找到了一些外显子(exon)簇,每个节点是一个外显子,有链接关系的外显子表明它们在大脑发育过程中具有协同作用。单个外显子可能的变异可能没有足够的样本来分析,但是外显子簇aggregate 了不同的外显子,它们可以具有各种各样的分子机制,可以借此推理可能的生物标记。最后可以用的得到的生物标记在电子医疗病历和保险数据上面做验证。这两类数据数据量都比较大的,有将近300万的病人,保险的数据有3400万的病人。在这样的一个大型数据集当中,可以验证找到的生物标记的有效性。这就是团队实验设计的总体思想。
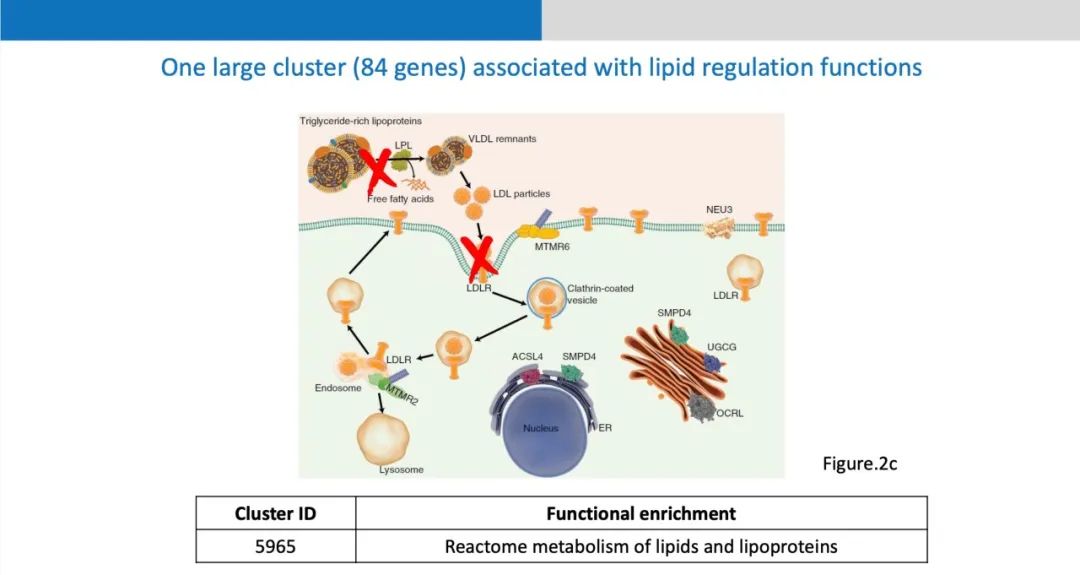
通过实验找到的外显子簇大小各异,图中这个外显子簇和脂蛋白代谢非常相关,脂蛋白通过脂蛋白水解酶和细胞表面上的low-density-lipoprotein receptor的作用下,把这些脂分子吸收到细胞里面来,生产一些对大脑有用的分子。大脑皮层很大一部分的组成成分就是lipid,如果这一过程遭到了破坏,整个脂蛋白合成和分解代谢就会紊乱,大脑皮层发育所需要的lipid分子不能够有效供应,从而可能导致大脑功能异常比如自闭症。在验证的第一步是通过这儿童医院的电子医疗病例的数据,来看脂蛋白的代谢异常和自闭症的相关性,看甘油三酯的成分在不同的性别,有没有肥胖以及不同的年龄段的分布,甘油三酯在自闭症和对照组人群当中都有很显著的不同。然后在保险数据上做验证,因为有些自闭症的病人会吃一些药,这些药可能导致肥胖。团队发现在区分有没有吃药的人群之后,自闭症和对照组在脂蛋白代谢异常方面依然有很显著的差异,这就进一步的说明了dyslipidemia有可能作为自闭症早筛的一个生物标记。
此外还有自闭症患儿的双亲,他们很多人其实也有着明显的脂蛋白代谢的异常,因为自闭症是一个遗传性的疾病,脂蛋白的代谢异常很有可能来自双亲尤其是母亲的遗传。这给团队提供了另一种思路,即不仅能够在婴儿刚刚出生的时候筛查脂蛋白代谢有没有异常,还可以看他的母亲在怀孕的时候脂蛋白代谢有没有异常。当然这个假设还是还是需要进一步的验证。这也是目前着重研究的一个方向,就是在母亲怀孕的时候能不能够找到一个有效的生物标记,从而对自闭症患儿更早的筛查。
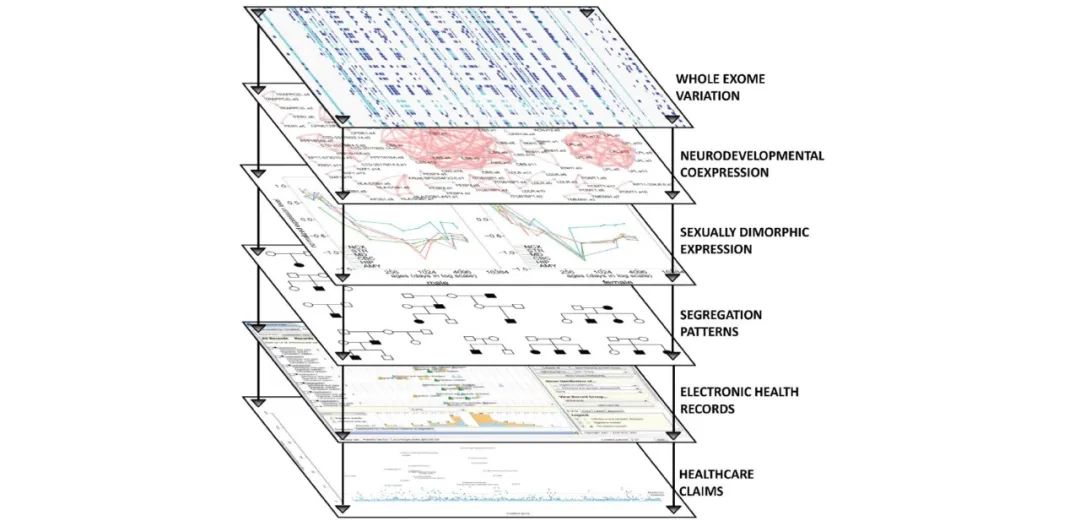
总结来说,正是因为能够把这么多种模态的有关生物和医疗的数据整合在一起、叠加到一块,才能够对病人的发病以及病情的发展有一个更加精准的认识,进而可以更加有效的进行干预。现在积累的医疗数据、模态、数据越来越多,一种模态或者是一些病人的数据现在越来越不足以能够支撑有效的科学研究以及新的科学发现。所以希望大家可以多考虑把数据共享,组成一些大的医疗网络进行合作。团队也非常欢迎和大家进行深入和广泛的合作。
以下为罗元教授讲座完整视频
精彩内容点击回放
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “清华大学智能产业研究院” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
-

-
北京
甲方 · 公立学校
未认证的机构号
最近发布
-
2023-04-29
-
2023-04-28
提名奖")











