
- 0
- 0
- 0
分享
- AIR DISCOVER|黄思远:类人的全面三维场景理解
-
原创 2021-12-15
12月9日傍晚,AIR DISCOVER青年科学家论坛第五期在清华大学智能产业研究院(AIR)图灵报告厅举行。本期活动荣幸地邀请到北京通用人工智能研究院通用视觉实验室负责人黄思远博士为我们作关于《Human-like Holistic 3D Scene Understanding》(类人的全面三维场景理解)的报告。

报告内容
随着科技的发展和新观念的产生,三维场景理解技术变得越来越重要:如果机器人拥有场景理解的能力,那么就可以帮人类完成更多的工作,一些新名词:元宇宙、虚拟旅行等产品的实现也都离不开三维场景理解,除此之外,三维场景理解还可以被用在其他各个行业中,比如用来评估房产等等。总之,三维场景理解技术,尤其是全面的三维场景理解,将在我们未来的生活中,甚至已经在我们目前的生活中,扮演非常重要的角色。
1.Human-like holistic的不同
目前已经成熟的三维场景理解,更多的是回答“what”和“where”的问题,即这个物体是什么以及它在哪里,而holistic 3D scene understanding 则是在此基础上,去探索“why”、“how”和“when”的问题,这需要对图片中的物体间底层逻辑关系有更深的理解,其难度也更大。现有的AI具有识别能力好、检测能力强、对于特定任务的准确率高等优点,但是不足之处在于:单个小任务往往需要前期巨大规模的数据训练,且表现不稳定,训练方法较简单。目前的AI,虽然在某些能力上超过了人类,但是在学习效率、掌握知识的灵活度、全面性、泛化能力上与人类还有较大差距。另外,人类在其他方面也表现出AI所不具备的优势:比如人类擅长在有限数据中学习多个任务,在交互中学习、以及人类的学习是不需要标签的等等。因此human-like holistic方法结合认知科学和神经科学对于人类认知机理的研究,对现有的三维场景理解进行改进。就像人一样,AI对于周围场景主要进行四个动作:感知,交互、学习和推理。黄思远博士着重介绍了前两部分。
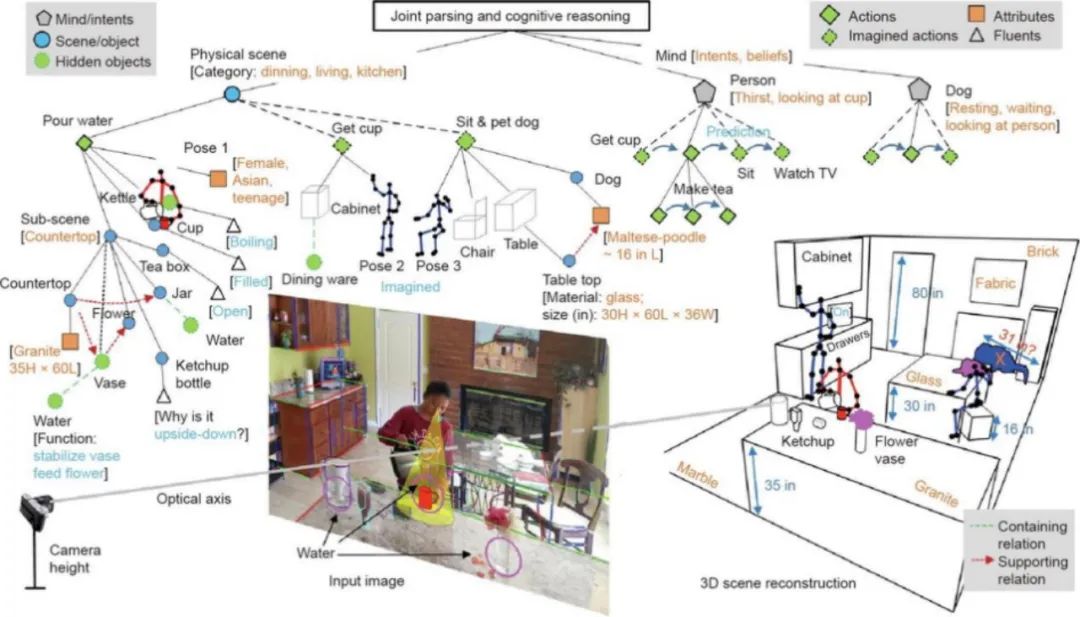
2.感知
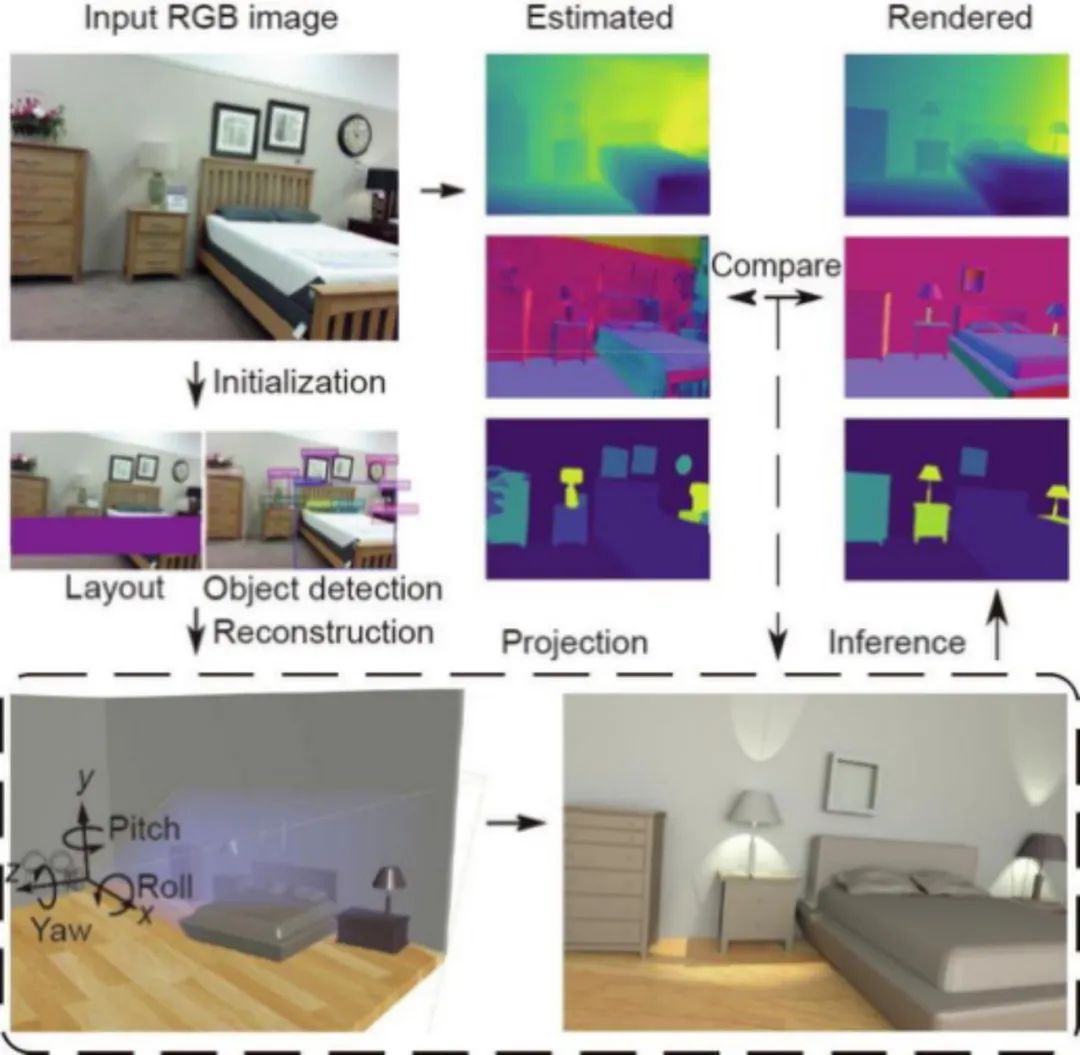
任务导向的三维场景解析和重建(Task-orinted 3d scene parsing and reconstruction):
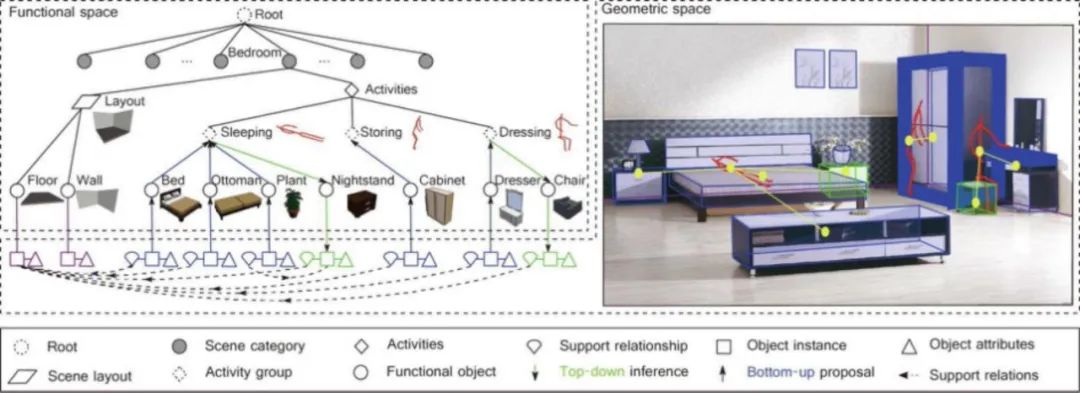
场景的表达,可以分为基于几何空间的表达和基于功能空间的表达,在几何空间中,表达出的是物体最基本的几何特征,而在功能空间中,表达出的是人的行为、人和场景所可能产生的交互等信息。通过analysis-by-synthesis、joint inference: depth、normal、segmentation等计算方法,进行初步的对环境的快速重建,接着采用map inference\mcmc with simulated annealing 的方法进行场景的优化。实验结果显示对于体积大的物体该方法有较好的效果。
3.交互
(1)人和物体的交互:
可以想像,从单张图进行人和场景的综合重建,是十分困难的,困难在于单张图中存在的物体间的遮挡会造成很大程度的信息缺失,针对这一问题的解决方法是:借助于人和场景交互相对关系的先验知识,来弥补信息不足的问题。考虑到现实世界中采集这些数据集成本很高,可以从大型游戏比如GTAV中抽取丰富的人和场景的交互信息作为先验知识,用来做场景重建。

可供性学习(affordance learning):
可供性是一个跨越场景和跨越类别的特征,比如一把椅子,它的每个部位的可供性是不同的:椅背可以用来背靠,扶手可以用来倚靠,椅面可以用来坐。既然每个部位可供性不同,那么自然要将每个部位单独从物体中区分出来,而这也是目前的困难所在。解决这个问题的传统方法是dense supervision,即用密集监督将每个像素点进行预测,但这种方法非常复杂,且泛化能力差,提供的解决方法是sparse supervision,通过简单的三维体素和可供性标注,用稀疏的数据让AI学习出物体各个部位的可供性。
(2)人和人的交互:
让AI学习人和人的交互,似乎是件困难的事情,黄思远博士给出了三种实现的方法,它们分别是:
1.multi-agent multi-task activities understanding
利用第一视角和第三视角的双数据集,让AI学习人和人在复杂场景下如何交流,如何合作。
2.Embodied reference understanding
方向性信号往往包含着丰富的信息,该方法通过语言信息加上“指”的动作,从肢体语言和自然语言结合的角度出发,让AI学习人和人之间的交互。
3.Human-gaze communication
通过对于人的眼神交流的学习,试图理解每一种眼神所代表的意图,该方法以社交网站中大量的社交视频为数据集。

关于 DISCOVER 实验室
DISCOVER实验室是AIR科研方向的横向支撑实验室之一,旨在利用机器学习、计算机视觉、计算机图形学、机器人学、运筹学、高性能计算与人机交互等前沿技术,围绕车路协同(V2I)、用户直连制造(C2M)、实验室自动化等各应用场景,构建以感知、规划、控制与决策为核心的智能算法平台体系,结合涵盖设计、工艺、计算与人因的智能系统架构体系,研究人-机-边-云四位一体的人在环路多智能体协同系统,开展具有创新性的算法理论与系统架构研究,紧贴以制造业为主的国家重点行业需求,攻克以人为中心的场景理解、人在环路机器学习、仿真到现实迁移与柔性制造工艺等关键技术瓶颈,与产业界深入合作探索自动驾驶与柔性制造的范式转移路径并实现关键技术验证与落地,推动我国在智慧交通和智能制造领域的产业升级。
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “清华大学智能产业研究院” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
-

-
北京
甲方 · 公立学校
未认证的机构号
最近发布
-
2023-04-29
-
2023-04-28
提名奖")











