
- 0
- 0
- 0
分享
- 大朋VR CTO | 如何理解VR的定位技术和实时感知算法
-
原创 2021-12-10
近日,大朋VR CTO 应骏博士在XXRI在线技术沙龙第36期做出如下分享:
随着Facebook公司改名Meta,在全球范围掀起VR/AR/MR的新一波元宇宙的浪潮。而这波浪潮对终端设备的实现提出了更多的技术要求:一是要求设备更加逼真地展现数字世界的内容,这个在数学上属于演绎学,在学术上的属于图形学的范畴;二是要求设备更加精确地感知外部真实世界,这个在数学上属于归纳学,在学术上属于图像学的范畴;三是因为应用方面更加强调互动,则对设备提出前两者的实时实现的要求,即需要我们寻找更加强大性能的承载平台。
前些年我们从业者在图形学方面,已经把显示分辨率从2K提高到了4K,甚至8K的性能,并在各自的设备中为了优化显示效果,增加了诸如抗畸变等多种有特色的改进功能。
今天我主要围绕如何做好更加精确地感知真实世界,和如何实时实现感知算法等两个方面进行展开阐述。
让VR终端设备精确地感知外部真实世界,主要分两个目标展开,一是定位技术,尤其是室内定位,即让设备理解“我在哪儿”的问题;二是动作捕捉技术,即让设备理解“我做了什么”的问题。两者合起来就是“位”“姿”检测技术。
位姿检测同样其他应用领域都得到广泛的应用,最早是机器人领域得到普及应用。但与机器人领域的位姿检测技术相比,VR领域的相关实现则有更高技术要求,同样实现带来更大困难,主要表现在如下两个方面:
(1)我们要检测的对象,即人体,是一个非刚体运动物体。而若需要对非刚体运动物体进行精确建模,不是简单的使用少数个传感器既能解决的。但在现阶段,VR领域一般对于使用者的位姿检测使用了双手+头部等三个目标标的物的若干传感器。在接下来的技术发展中,VR领域可能将会不断增加更多传感器、更多输入设备,从而使得在虚拟世界中能够建立更加逼真真实人体的模型和动作,从而提升使用体验。
(2)使用者对交互的实时性的敏感性非常高,因此也就要求VR终端对于位姿检测到人体建模过程必须实时实现,否则会非常容易带来头晕等较差的用户体验。
我们在VR终端设备实现中,从位姿检测的传感器部署模式、传感器类型及其技术发展等方面展开了解相关技术原理、特征、实现难点、以及我们可能的对策。
位姿检测的实现系统存在两者部署模式:Outside-In模式和Inside-Out模式。两者部署模式有各自的适应访问、各自的优点和缺点。
Outside-In模式是将传感器部署在与头盔或者人体无直接连接的周边环境,一般是在大于使用者的活动空间的部署相关传感器。因传感器之间的物理尺寸会大于使用者的运动范围,相比Inside-Out相对更加方便地获得更加精确的定位信息。而一般此类传感器检测范围较大,可以支持多人互动应用场景。但这种模式下,传感器的部署是有一定的难度,并牺牲了系统的便携性。
Inside-Out模式是将传感器放在头盔或者人体佩戴等与使用者直接连接的位置,通过从使用者出发的传感器检测周边场景中固定物体的距离变化,从而反向推送使用者的位姿变化值。这种部署模式符合人体仿生学的实际情况,有很好的便携性。但增加了定位算法难度,或者增加了获取同样精度结果的运算量。
历史上典型的Outside-In定位系统,可以从GNSS全球导航卫星系统说起,很多近些年的无线定位系统,在一定意义上会借鉴GNSS系统的部署方式、基站时间同步机制、定位算法等技术。

GNSS系统因为定位基站部署在卫星轨道上,其传感器本体的物理尺度远大于定位对象的尺寸,初期系统就获得军工级别的定位精度。反而后来的各种技术都是在定位信号中人为添加扰码,从而降低民用定位系统的精度。这种反向发展也是人类技术发展过程中唯一的例外。但GNSS系统因为信号遮挡的原因,无法应用于室内场景,无法被使用在VR相关应用场景,其仅是我们后续更多系统的技术借鉴原型。
典型的室内定位系统有WIFI/Zigbee/BLE定位系统、UWB定位系统、光学定位系统。因基站部署尺度远无法比拟GNSS系统,所以一般实现系统中,其精度还是有待提高的。目前商业系统中,WIFI/Zigbee/BLE等2.4G无线信号定位系统的定位精度大约几十厘米范围,典型值为50cm,该定位精度可以适合类似商业广告推送的应用。商业的UWB定位系统的典型定位精度为10cm,可以符合较多工业系统中的应用。上述相关定位系统其精度不太满足VR应用对精度的要求。而光学(含激光)定位系统因不同的定位机制和算法,可以获得亚厘米至亚毫米级别的精度,在VR系统中得到广泛的应用。
VR应用中,典型的光学定位系统可以有如下系统:
1.OptiTrack系统,该系统通过部署较多的高速摄像机,对场景中的人体进行位置检测和姿态识别。该系统适合多人大场景的互动应用,一些低成本制作的科幻电影是采用OptiTrack系统进行人体建模并拍摄制作完成的。

2.Valve的Lighthouse系统,它可以两个基站完成小场景下单一人员的360°定位和位姿检测;也可以通过部署更多基站完成大场景下的多人位姿检测工作。

3.大朋VR推出的Polaris系统,也是典型的Outside-In系统。它支持一个基站180°的单一人员的位姿检测,两个基站360°的多人的位姿检测,具有非常灵活的部署方法。

Inside-Out部署的系统实现,会依赖常见的几种传感器:
MEMS IMU传感器,该传感器相对容易获取,应用系统简洁,在VR 3DOF系统中常见。但该传感器具有零漂、温漂等效应,会导致长时间运行带来较大的累积误差。

激光雷达是无人车领域常见的传感器,该传感器依靠高精度高稳定度的旋转机械搭载高功率激光测距传感器,实现远距离高精度的距离检测,非常适合无人驾驶应用,但其价格非常昂贵。
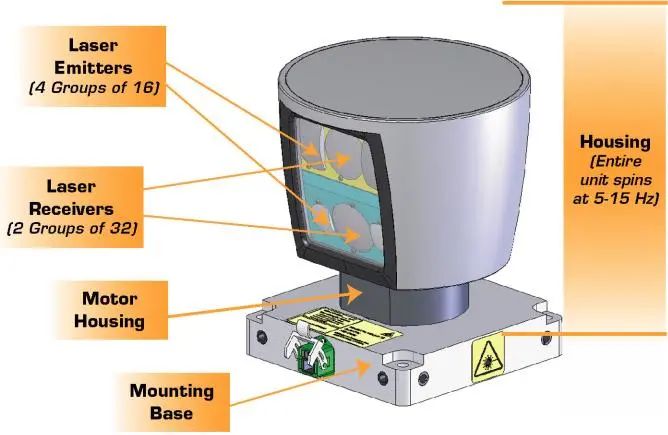
另一种非常有前景的传感器是采用多种不同技术实现的深度相机,在近些年新兴的传感器。其直接输出检测物体前方面阵深度图,直接获取前方物体或者场景的远近信息,此类设备的成熟,将会大大简化各种定位系统、目标检测系统的实现难度,应该是未来非常有前景的设备。
这里简单介绍一下深度相机的几种技术实现方法:
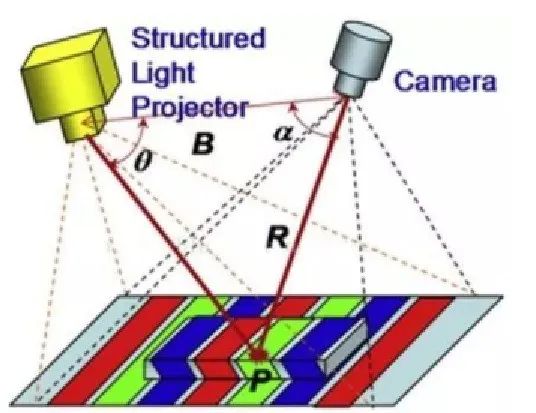
第一种是结构光深度相机,该相机是通过结构光发生投影仪向前方投射一定几何图形的图形,相机通过检测该图形投影变化,从而计算得出其距离信息。这种技术实现设备是目前深度相机中精度最高的,其在很多医学领域得到广泛的应用,典型应用是皮肤病医院利用该设备完成病人的皮肤建模,从而分析皮肤的变化模型,来评估治疗效果。但这种技术实现最大缺点是成像速度不足,或者达到实时30fps的设备比较昂贵。
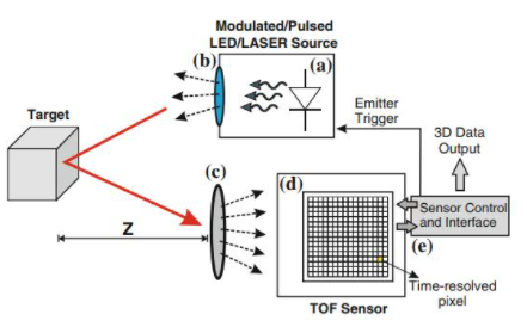
第二种是采用TOF面阵的深度相机,TOF面阵是一个面阵传感器直接测量红外激光发射的激光从相机到物体表面的来回飞行时间,从而得出该物体与相机的距离信息。这是深度测量中最直接的检测方式,对后端算法系统的计算量要求是最少的。也是未来对各类距离检测系统可能会带来具体变化和影响传感器。但该技术实现设备存在分辨率不足(典型系统为320x240分辨率),且其测量距离大概在1%左右,可能还不满足当前VR应用的需求。
第三种是采用视觉的方式,通过双目或者多目摄像机计算匹配对象物体的视场差来推算其距离信息。该技术实现是典型的被动视觉处理系统。其依靠大量的视觉图像处理算法,实现目标图像中的纹理或者角点匹配之后的视场差计算,从而获得深度信息。虽然其具有海量的图像处理运算算力要求,但随着近些年处理器(算力)的快速降低成本,反而是最具价格优势的一种技术实现路径。但该传感器最大缺点是其算法非常依赖场景中的环境光,可能会带来算法的稳定性问题。
利用上述多种传感器实现位姿检测,其常见采用SLAM算法实现。SLAM(同时定位和建图)最先在机器人领域得到广泛应用,是机器人进入到未知场景中,如何在摸索/探索中,进行自身位置定位和未知场景的地图重建工作。现在在各类工业机器人、扫地机器人、无人驾驶汽车等相关领域取得良好的应用效果。目前在VR的位姿检测应用场景,出现采用SLAM算法作为位姿检测的6DOF系统,获得较好的用户体验,带来更多的互动类应用,拓展了VR应用内容互动方式。
观察前述SLAM系统可能使用的传感器,当前VR应用中,为了兼顾实现精度、速度和成本等因素,通常采用视觉(V)+惯性传感器(I),构成VISLAM实现系统。其中视觉传感器具有信息丰富、静止时无累积误差的特征,但具有易受光照等环境光的影响,会存在运动物体干扰或者遮挡等因素造成的信息缺失等问题;IMU单元则具有可以快速捕获载体运动信息,不受光照等环境干扰的优点,但也存在零漂、温漂、易受振动干扰等缺点。目前认为两者是天然可以互相弥补的传感器,因此结合两种传感器同时应用的VISLAM系统可以完美地获取相应的位置,并构建良好的环境地图,从而使得VR系统可以精确捕获位姿信息。
VISLAM也叫做视觉惯性导航系统(VINS),其算法实现框架见下图:
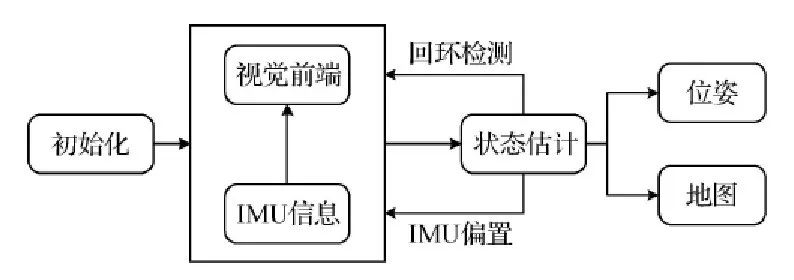
在学术界,很多人会在算法框图的各个环节,如初始化、图像视觉前端处理、状态估计、地图构建和维护、信息融合、评测工具与方法、引入深度学习方法等关键技术上进行优化和研究,发表众多的论文及成果,是学术界非常活跃的分支。
近些年该领域最具影响力的开源实现参考代码是ORB-SLAM3系统。从2015年首次发布ORB-SLAM系统,建立初始开源代码。2017年引入视觉传感器,发布ORB-SLAM2系统。在2020年7月,由Campos发表的论文,向大家引荐了ORB-SLAM3系统,是目前公认的兼顾精度和算法复杂度的SLAM算法,也是推荐大家可以关注的参考开源SLAM算法程序。
而对于我们VR领域,不仅仅需要学习优秀的SLAM算法代码,同时因为实时性的要求,需要考虑在算法落地时,需要考察算法的特征,从而选择更加合适的算力平台,达到实现代价和实现效果的平衡。
VR应用中的VISLAM实现,通常采用双目,甚至四目相机,输入的图像帧率非常高,图像处理的运算复杂度非常高,不是简单选择某个通用处理器即可满足实时实现。
深入考察VISLAM程序代码,尤其是图像处理的算法,会有如下特征:
l 高密集的数据处理,且大量为INT8类型短数据处理
l 相同的算子重复性非常高
l 且未来存在加入AI算子的可能性(高密集乘累加算子)
这样的算法特征,是需要高度并行的计算架构来支撑的。一般说来,经典DSP架构是最适合上述算法实现的平台,如TI DSP内置(.L .S .D .M)四种运算单元,各两套,可以针对不同运算获得较好的加速。而GPU或者AI芯片,因高度并行运算架构,也存在大量硬件乘法单元,也可以获得一定的加速。
具体分析下面几个芯片架构,我们可以得出如下结论:
l IA架构(PC/笔记本/服务器)因为其MMX及SSE2等多媒体扩展指令,在指令集可以做到对图像处理很高的加速比;(高)
l TI或者ADI的通用DSP芯片,因为其高度并行运算单元,超长指令VLIW结构、超长流水线等特征,也可以获得很高的图像处理算法的并行加速比;(高)
l ARM A系列的NEON指令,也具备一定的多媒体指令加速能力,对图像处理可以获得部分加速;(中)
l RISC-V的Vector指令,也有一定的多媒体算法加速能力;(中)
l GPGPU或者AI芯片因密集的乘累加单元,获得部分多媒体算法加速(中高)
除了选择合适的平台,在实时实现VISLAM算法时,还存在如下困难:
(1)软件发展过程中,强调良好的代码封装,是软件工程的基础。而控制代码封装对代码执行效率的损失,是良好的编译器能够做到的。好的编译技术是软件领域飞速发展的保障。但软件行业中,目前没有很好的并行编译器,尤其是针对各类不同的异构处理器的并行编译器。导致大多数类似图像处理算子的并行处理程序,需要手工优化,才能发挥各类并行处理器的加速效果。从而导致哪怕选择较好的处理器平台,仍然需要较高的程序优化代价,最终使得算法实时实现的成本居高不下。
(2)图像处理算法是面向数据流密集型的算法模型,而传统的程序设计思想大多是以面向控制密集型的设计模式。这也是图像处理算法优化中,很多时候良好的图像处理算法需要时刻思考如何使得数据流的走向是紧凑的,而不是思考如何控制程序节奏是否衔接合理。
(3)各类处理器为了获得较高的并行加速效果,通常会引入超长流水线等硬件结构。而为了发挥超长流水线的效率,很多时候程序优化思路会采用去除分支结构、去除函数调用、展开循环结构等与软件工程提倡的行为所相悖的方法。同时上述处理,还会带来代码可读性的降低,可维护性的降低。如何做到这些方法的权衡,也是一个有挑战的事情。
为了应当上述提出的各类难点,行业的做法通常是利用在某些架构平台已经优化的图像处理算法库来加速自己的程序优化实现。如:
l OpenCV是图像处理领域的准优化实现事实标准,它是2000年由Intel首次提出并推动的在IA架构上的图像处理加速库。因此也使得IA平台在图像处理领域可以获得较好的实现效果。虽然OpenCV在ARM等各类其他平台有编译库,但其优化效果还是离IA架构有一定差距。
l Khronos集团(OpenGL、OpenCL的维护者)也在近些年提出了芯片领域针对图像处理的开放接口OpenVX,这将加速各类异构处理器在图像处理领域的互操作性,但其标准尚待推广中,我们可以期待未来在该方面看到较好的产品出现。
l GPU领域是近些年发展较快的领域,其具有强悍的并行能力,基于GPGPU架构的OpenCL标准,对图像处理可以做到间接的加速效果,很多同类型芯片可以利用这些便利优化成果。
但在性能不足时,很多高级的团队,在使用OpenCV等类似加速库的基础上,仍然需要采用手工优化去提升加速性能,在极致成本竞争时,这个技能和路径,我们是需要关注的。
在上述各类理论讲述后,我们再观察当前可以支持VISLAM实现的各类平台,以及我们可能的实际选择情况如下:
在传统VISLAM应用领域,如机器人等具有较高成本承受能力的应用场景,最直接的做法是直接使用IA架构的设备,如工控机、PC机、NUC等设备,嵌入到机器人设备中。这是最常见的机器人设备公司的做法。该领域具有一定优化开发能力,并对成本有一定敏感的应用场景,一般会采用通用DSP处理系统,可以获得成本和功耗的一定优势。
但在VR应用场景,因成本和功耗的约束,我们当前可能可选的平台可能会约束到如下几种:
TI的ARM+DSP平台,如Jacinto系列中相对低端点的平台,或者选择某个有成本优势的DSP作为协处理器。但TI平台的坏处是TI公司作为经典芯片供应商,一般仅提供常见软件和SDK,很多行业性软件需要我们自己搭建,可能开发工作量较大;
Intel Movidius处理器:Movidius公司是一群TI的人员创业的公司,其架构天然是一个DSP架构(非典型的AI芯片),虽然其是作为AI处理器被大多数人所认知的。其SDK是同时具有AI接口库和OpenCV加速库的,是VISLAM较好的实现平台;
其他内置DSP的SoC平台,如高通的XR1和XR2,其都是内置高通Hexagon V65 DSP核,可能是当前VR应用较好的VISLAM实现平台。还有国内公司推出的AR9331芯片,也是内置了CEVA DSP的加速核,提供支持OpenCV加速库的SDK,大家可以去尝试在相应平台上进行VISLAM算法的实现和测试。
选择合适的平台,我们就需要搭建相应软件优化团队,采纳类ORB-SLAM3的优化实现程序,进行性能优化和测试。程序优化是无止境的,同时也是逐步求精的过程,期望大家能够最终给出兼具精度和速度的位姿检测的最终实现,从而完成VR领域的6DOF设备。
我们这里再展望一下位姿检测中VISLAM算法的发展。在算法方面,因为是新近的成果,学术界也是非常活跃,我们需要时刻关注相应的论文成果,不仅仅包括各个算法子模块的优化方法,同时包括最新的引入AI算法的可能发展趋势。可能这类带自学习功能的成果会解决当前VISLAM算法在大空间场景的迷失问题、检测的普世性问题等。当然,若引入AI算法,对于加速平台可能需要关注兼具DSP和AI加速核的芯片。
站在设备实现角度,我们需要关注前文提及的各类在发展中的其他室内定位技术,当那些技术成熟到某个临界点,可能会带来对当前VISLAM构成完全不同异构竞争。如前述TOF深度相机解决分辨率问题和精度问题,结构光深度相机解决速度问题和成本问题,均具有很强的竞争力。
而站在VR应用角度,面向非刚体运动物体的人体,高精度建模的需求会带来更多的关键节点上增加传感器的需求,这也是未来可能的发展趋势。
VR应用、AR应用、以及MR应用要切入到日常生活中,多人大场景互动应用很可能会开创很不一样的需求。那么也许传感器就需要Outside-In的部署模式与Inside-Out部署模式需要做深度融合,从而导致更新的实现方式。
这里预告一下,
大朋VR将于2022年推出基于VISLAM的创新产品
届时欢迎大家体验!也希望欢迎大家留言讨论

-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “大朋VR” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
-

-
金华
分包方 · VR/AR
未认证的机构号
最近发布
-
2023-05-16
-
2023-05-16












