
- 0
- 0
- 0
分享
- AIR DISCOVER|高阳:EfficientZero——高效训练的超人类水平智能体
-
原创 2022-04-26
活动概况
4 月 21 日,AIR DISCOVER 青年科学家论坛第九期在清华大学智能产业研究院(AIR)图灵报告厅如期举行。本期活动荣幸地邀请到清华大学交叉信息研究院助理教授高阳,并由他为我们作题为《EfficientZero——高效训练的超人类水平智能体》的报告。

讲者介绍

高阳,清华大学交叉信息研究院助理教授,博士生导师,研究方向为计算机视觉和强化学习。2014年于清华大学计算机系获得工学学士学位,2019年于美国加州大学伯克利分校获得博士学位,导师为Trevor Darrell教授。先后在相关领域发表国际顶级期刊及会议文章十余篇,包括NeurIPS,CVPR,ICRA等。
报告内容
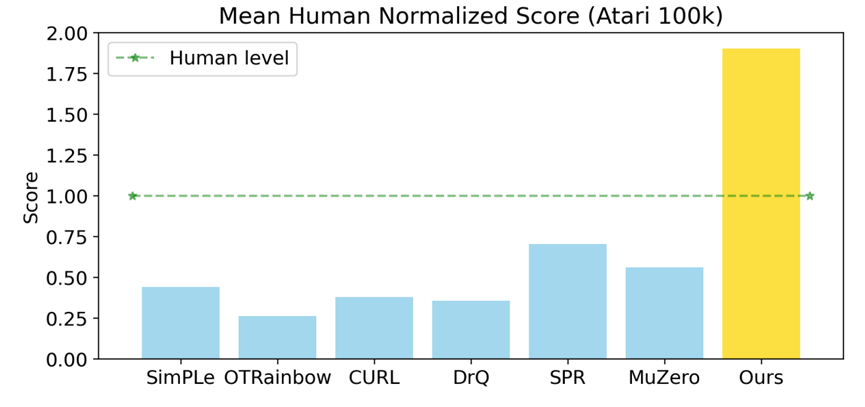
EfficientZero能在帧数限定100k的情况下取得超人类的性能
深度强化学习目前已经在围棋、电子游戏和工业控制等领域取得了超人类水平的性能。然而,其数据利用率依然不够高,智能体需要在仿真环境中进行天文数字时长的训练才能掌握特定的技能。针对这一问题,学术界最近将高样本利用效率的深度强化学习作为了研究热点之一。
其中,高阳教授的研究组提出了新的Atari 100k benchmark和EfficientZero算法。该算法被NeurIPS 2021接受,在学术界和工业界引发了广泛的关注与讨论。这一新的测试基准将Atari游戏的帧数限定在100k以内,对应约两个小时的人类游戏过程。如果算法能在这一限制内取得较好的性能,便可以一定程度上验证其具有类人的数据利用效率。如上图所示,其他六个前人提出的高效强化学习算法均无法达到人类水准,而EfficientZero的性能却能远超人类水准。
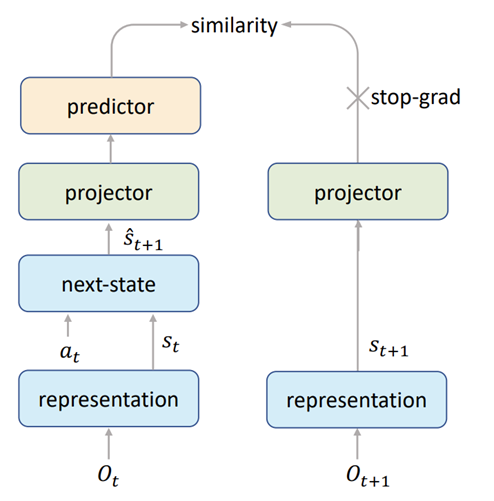
EfficientZero提出的自监督状态表征学习范式
EfficientZero是一个基于蒙特卡洛树搜索的方法,以往的方法如MuZero受限于只建模value和reward,不能刻画系统状态的完整分布。为了改善这一问题,高阳教授的研究组提出了上图所示的自监督状态表征学习范式。该方法利用表征学习网络从两帧图像输入中提取状态特征向量,然后进入世界模型网络next-state,以动作为输入预测下一帧的状态。当下一帧状态的预测值和真实值被更多的神经网络层映射后,该方法再进行自监督表征学习。与传统的图像自监督深度学习不同,上述情况下,下一帧真实状态特征对stop-gradient trick的应用更为自然。
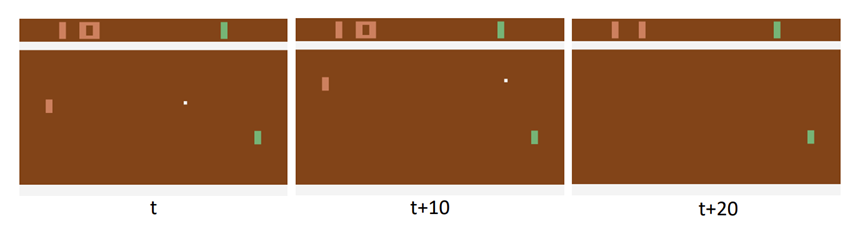
Reward的模糊性示意图
此外,高阳教授的研究组还指出了reward的模糊性问题。如上图所示,人类很早就能判断出小球必然飞出边界,因此不会去关注具体的飞出时刻。但是神经网络只能在飞出边界的时刻获得奖励,因此需要学习一个很难被拟合的监督信号,这也就降低了强化学习的样本利用效率。对此,EfficientZero的解决方法是将奖励值累加作为监督信号,让算法学到某个区间内发生了奖励这一信息。与此同时,EfficientZero还将传统的n-step bootstrapping方法结合蒙特卡洛树搜索,进行了自适应参数调整。
通过前述几个创新技术的结合,EfficientZero展现出了极高的样本利用效率。
报告结束后,现场的老师同学们与高阳教授积极互动,就技术细节与学术趋势展开了热烈的讨论。高阳教授认为,reset-free的强化学习是一个未来的趋势。现有的强化学习算法需要在一个决策序列结束后进行环境重置,而最近提出的一些方法能利用多任务学习减轻重置负担,有望让真实世界中不断探索学习的智能体更快到来。
AIR始终秉持利用人工智能技术赋能产业升级、推动社会进步的使命,致力于为老师同学们提供更多类似的前沿理论交流与实践探索的机会。在此,欢迎感兴趣的同学们报名参加AIR DISCOVER 2022 暑期夏令营活动。详情请戳:AIR DISCOVER 2022 夏令营开始报名啦!
参考文献
Ye W, Liu S, Kurutach T, et al. Mastering atari games with limited data[J]. Advances in Neural Information Processing Systems, 2021, 34.
Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
Grill J B, Strub F, Altché F, et al. Bootstrap your own latent-a new approach to self-supervised learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 21271-21284.
Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering atari, go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588(7839): 604-609.
Kaiser L, Babaeizadeh M, Milos P, et al. Model-based reinforcement learning for atari[J]. arXiv preprint arXiv:1903.00374, 2019.
Hafner D, Lillicrap T, Ba J, et al. Dream to control: Learning behaviors by latent imagination[J]. arXiv preprint arXiv:1912.01603, 2019.
Asadi K, Misra D, Kim S, et al. Combating the compounding-error problem with a multi-step model[J]. arXiv preprint arXiv:1905.13320, 2019.
关于 DISCOVER 实验室
DISCOVER实验室是AIR科研方向的横向支撑实验室之一,旨在利用机器学习、计算机视觉、计算机图形学、机器人学、运筹学、高性能计算与人机交互等前沿技术,围绕车路协同(V2I)、用户直连制造(C2M)、实验室自动化等各应用场景,构建以感知、规划、控制与决策为核心的智能算法平台体系,结合涵盖设计、工艺、计算与人因的智能系统架构体系,研究人-机-边-云四位一体的人在环路多智能体协同系统,开展具有创新性的算法理论与系统架构研究,紧贴以制造业为主的国家重点行业需求,攻克以人为中心的场景理解、人在环路机器学习、仿真到现实迁移与柔性制造工艺等关键技术瓶颈,与产业界深入合作探索自动驾驶与柔性制造的范式转移路径并实现关键技术验证与落地,推动我国在智慧交通和智能制造领域的产业升级。
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号清华大学智能产业研究院 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
数字媒体艺术 高阳 人类水平智能体 青年科学家论坛 清华大学智能产业研究
-

-
北京
甲方 · 公立学校
未认证的机构号
recently released
-
2023-04-29
-
2023-04-28
提名奖")










