
- 0
- 0
- 1
分享
- AIR学术|南洋理工刘子纬:大模型时代下的3D AIGC
-
2023-04-24
4月20日,由DISCOVER实验室主办的第21期AIR青年科学家论坛如期举行。本活动有幸邀请到南洋理工大学助理教授刘子纬,为AIR的老师和同学们做了题为Visual AIGC with Foundation Models(大模型时代下的3D AIGC)的精彩报告。

讲者介绍

刘子纬,新加坡南洋理工大学助理教授,并获得南洋学者称号(Nanyang Assistant Professor)。他的研究兴趣包括计算机视觉、机器学习与计算机图形学。他在国际顶级会议及期刊(CVPR / ICCV / ECCV / NeurIPS / ICLR / TPAMI / TOG / Nature - Machine Intelligence)上发表文章100余篇,总引用量2万余次,获得专利50余项。他领导搭建了数个国际知名的基准数据库,例如CelebA和DeepFashion等。同时他也领导数个广泛使用的开源软件建设,例如MMFashion和MMHuman3D等。他获得过多个领域内奖项,包括微软小学者奖、香港政府博士奖、ICCV青年学者奖、HKSTP最佳论文奖和WAIC云帆奖等。他是国际顶级会议CVPR、ICCV、NeurIPS和ICLR的领域主席(Area Chair)以及国际顶级期刊IJCV的编委(Associate Editor)。
报告内容

最近爆火的GPT4,Stable Diffusion等都需要提示词去引导,那么对于一个非专业的人士,并不知道如何去写提示词,这该怎么办呢?
刘子纬博士在这篇工作中通过学习的方法来写提示词,使得识别精度大大提升。

目前LoRA,Adapter等微调私有数据的方法相当火爆,刘子纬博士观察到对于不同的任务需要微调的模型位置不同,进而提出了更通用,更灵活的微调模型NOAH,甚至可以在全新的任务中泛化。

深度学习一直都是数据驱动的,刘子纬博士这篇Bamboo数据集,在数据层面上做了很大的提升,使得分类等任务的性能较之于ImageNet更好。
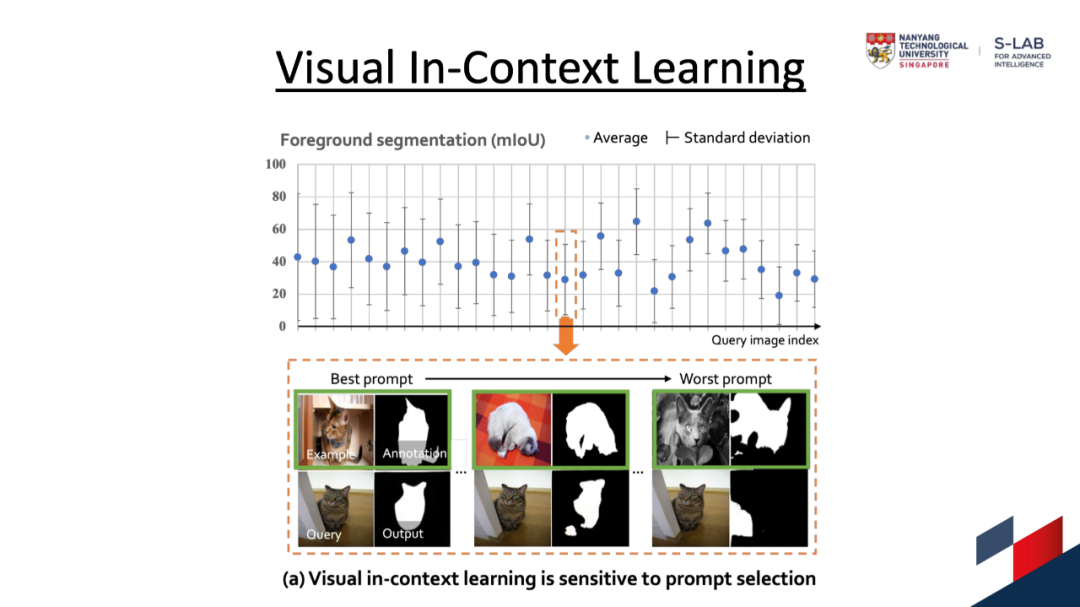
这篇工作借鉴了自然语言处理领域中的Few-shot思路,给定3到5个分割样例,模型就能知道要干什么并且在新的数据上表现良好。
随后刘子纬博士向我们介绍他在生成上所做的工作。
首先他从一个三角形开始讲起,顶点分别为虚拟人(Avatar),物体(Object)和场景(Scene),代表三个不同的领域。

在Avatar方面,刘子纬博士依次介绍了StyleGAN-Human, Text2Human, Text2Performer,EVA3D,AvatarCLIP和MotionDiffuse等高质量文章。

首先是StyleGAN-Human,这篇工作收集并注释了一个大规模的人体图像数据集,并研究了基于StyleGAN的人体生成的三个基本因素,分别为数据规模、数据分布和数据对齐。

其次是Text2Human,这篇工作十分有趣,通过用户的沟通(语言或涂鸦等),来进行人体结构和纹理的组合,进而达到生成的可控。

第三篇工作为Text2Performer,解决了文本驱动的人类视频生成问题。通过一段描述目标人物外观和动作的文本,算法可以合成一段连续的视频序列。

之后是EVA3D,这篇工作是首个从海量的二维图像集合中生成高分辨率三维人体的方法。EVA3D提出了一种全新的人体NeRF表达,通过建立多个局部的NeRF,方便的人体姿势以及形状的控制,同时对采样和训练也十分高效。

AvatarCLIP向我们展示了通过Zero-shot文本驱动的方式,来实现三维虚拟人的生成,如“生成一个又高又胖的钢铁侠在跑步”,相当有趣。
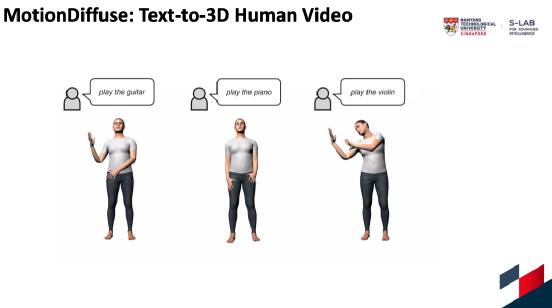
最后是MotionDiffuse,刘子纬博士介绍道,在生成的过程中,生成动作往往要比生成人困难得多。而这篇工作第一个将扩散模型引入人的动作生成中,给定一段文字,如“像僵尸🧟♂️一样行走”,MotionDiffuse就可以生成一段对应动作的30秒长视频。
之后刘子纬博士介绍了物体层面生成的相关工作:

OmniObject3D在最近的CVPR 2023 被评选为Award Candidate(12/9155),角逐Best Paper。这篇数据集工作包含了6000个高质量的真实三维模型,涵盖190个类,有4种不同的模态,也支持非常多的下游任务,对于计算机视觉的发展有着重大的意义。

Voxurf是一篇多视角重建的工作,通过引入三维先验,模型可以重建地又快又好,仅仅几分钟就可以将一个物体重建地非常精细。
其次刘子纬博士向我们介绍了场景生成的相关工作:

通过一段文字,Text2Light可以生成一个4K分辨率的HDR全景图片,用户可以在生成的全景图中放置物体,其反光感是十分真实的。该工作可以生成室内和室外的图片,已被引入Blender引擎中。

SceneDreamer这篇工作通过二维的图像集合,可以生成无限的几何一致的三维场景。

F2NeRF同样是一篇重建的工作,是CVPR 2023的HighLight。这篇工作解决了NeRF受限于轨迹的问题,用户只需一台手机随意地拍摄,就可以达到高清的重建效果。
在介绍完三个不同领域的生成工作之后,刘子纬博士认为两两之间也必然存在联系。
首先刘子纬博士先介绍了虚拟人与场景之间的联系:

不同于之前的人体打光方法,要么使用较为昂贵的灯光舞台的一次光照,要么使用合成数据,而Relighting4D可以实现在未知的光照下从人体视频中自由地重新打光。

DiffMimic这篇工作通过物理仿真,通过建模一定的物理属性(如摩擦力等),有效地模拟出参考人物的动作。同时支持许多下游任务,如用语言控制动作等。
最后刘子纬博士介绍了物体和环境相联系的工作Reversion。

该篇工作通过给定一些示例图像,其中一个关系在每个图像中共存,通过对比学习来学习到形容词、介词和名词之间的分布来找到一个关系提示以捕获这种互动,并将这种关系应用于新的物体中,如“蜘蛛侠在篮子中”等,非常有意思。
报告结束后,刘子纬博士与参会的老师和同学们对报告中的技术细节和领域前沿进展进行了热烈的讨论
个人主页:https://liuziwei7.github.io/
AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR
关于DISCOVER实验室
关于DISCOVER实验室
DISCOVER实验室是AIR科研方向的横向支撑实验室之一,旨在利用机器学习、计算机视觉、计算机图形学、机器人学、运筹学、高性能计算与人机交互等前沿技术,围绕车路协同(V2I)、用户直连制造(C2M)、实验室自动化等各应用场景,构建以感知、规划、控制与决策为核心的智能算法平台体系,结合涵盖设计、工艺、计算与人因的智能系统架构体系,研究人-机-边-云四位一体的人在环路多智能体协同系统,开展具有创新性的算法理论与系统架构研究,紧贴以制造业为主的国家重点行业需求,攻克以人为中心的场景理解、人在环路机器学习、仿真到现实迁移与柔性制造工艺等关键技术瓶颈,与产业界深入合作探索自动驾驶与柔性制造的范式转移路径并实现关键技术验证与落地,推动我国在智慧交通和智能制造领域的产业升级。
往期精彩:
张亚勤:大模型时代,中国AI行业的机遇与挑战
祝贺!AIR获ICLR 2023杰出论文提名
亚信科技与清华大学智能产业研究院共建“6G网络与智能计算联合研究中心”
亚信科技、清华大学智能产业研究院联合发布《AIGC(GPT-4)赋能通信行业应用白皮书》
全球首届车路协同自动驾驶算法挑战赛公布获奖名单
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “清华大学智能产业研究院” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
数字媒体艺术 新媒体艺术 科技艺术 AIR学术 3D AIGC
-

-
北京
甲方 · 公立学校
未认证的机构号
最近发布
-
2023-04-29
-
2023-04-28
提名奖")











