
- 0
- 0
- 0
分享
- LLM推理3倍速!微软发布LLM Accelerator:用参考文本实现无损加速
-
2023-05-23

新智元报道
新智元报道
【新智元导读】最近,微软亚洲研究院的研究员们提出了一种使用参考文本无损加速大语言模型推理的方法 LLM Accelerator,在大模型典型的应用场景中可以取得两到三倍的加速。
随着人工智能技术的快速发展,ChatGPT、New Bing、GPT-4 等新产品和新技术陆续发布,基础大模型在诸多应用中将发挥日益重要的作用。
目前的大语言模型大多是自回归模型。自回归是指模型在输出时往往采用逐词输出的方式,即在输出每个词时,模型需要将之前输出的词作为输入。而这种自回归模式通常在输出时制约着并行加速器的充分利用。
在许多应用场景中,大模型的输出常常与一些参考文本有很大的相似性,例如在以下三个常见的场景中:
1. 检索增强的生成
New Bing 等检索应用在响应用户输入的内容时,会先返回一些与用户输入相关的信息,然后用语言模型总结检索出的信息,再回答用户输入的内容。在这种场景中,模型的输出往往包含大量检索结果中的文本片段。
2. 使用缓存的生成
大规模部署语言模型的过程中,历史的输入输出会被缓存。在处理新的输入时,检索应用会在缓存中寻找相似的输入。因此,模型的输出往往和缓存中对应的输出有很大的相似性。
3. 多轮对话中的生成
在使用 ChatGPT 等应用时,用户往往会根据模型的输出反复提出修改要求。在这种多轮对话的场景下,模型的多次输出往往只有少量的变化,重复度较高。

图1:大模型的输出与参考文本存在相似性的常见场景
基于以上观察,研究员们以参考文本与模型输出的重复性作为突破自回归瓶颈的着力点,希望可以提高并行加速器利用率,加速大语言模型推理,进而提出了一种利用输出与参考文本的重复性来实现一步输出多个词的方法 LLM Accelerator。
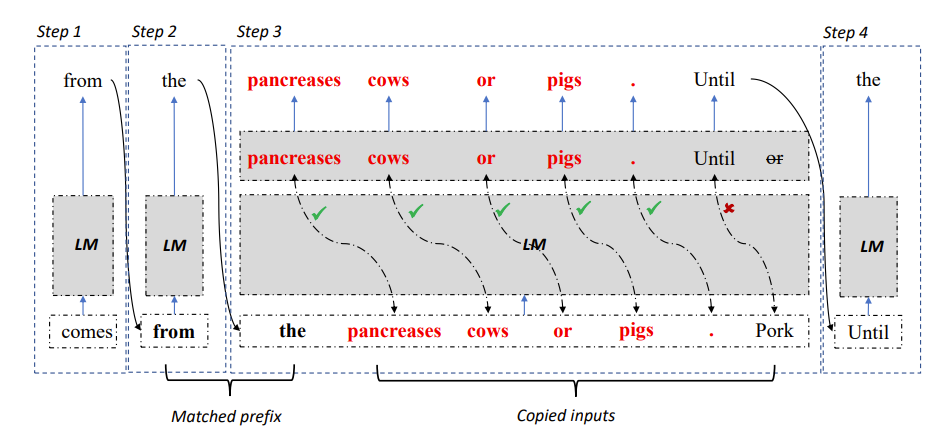
图2:LLM Accelerator 解码算法
具体来说,在每一步解码时,让模型先匹配已有的输出结果与参考文本,如果发现某个参考文本与已有的输出相符,那么模型很可能顺延已有的参考文本继续输出。
因此,研究员们将参考文本的后续词也作为输入加入到模型中,从而使得一个解码步骤可以输出多个词。
为了保证输入输出准确,研究员们进一步对比了模型输出的词与从参考文档输入的词。如果两者不一致,那么不正确的输入输出结果将被舍弃。
以上方法能够保证解码结果与基准方法完全一致,并可以提高每个解码步骤的输出词数,从而实现大模型推理的无损加速。
LLM Accelerator 无需额外辅助模型,简单易用,可以方便地部署到各种应用场景中。

项目链接:https://github.com/microsoft/LMOps
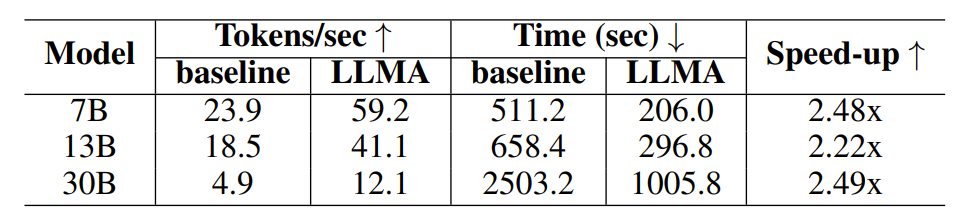
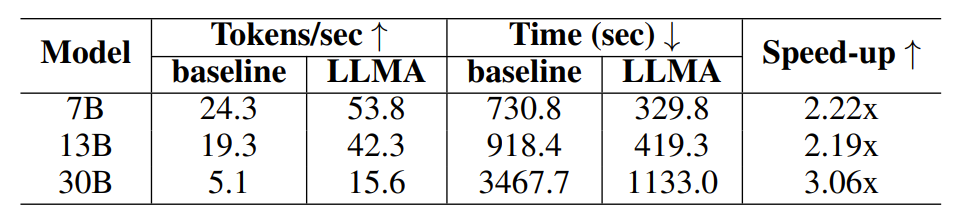


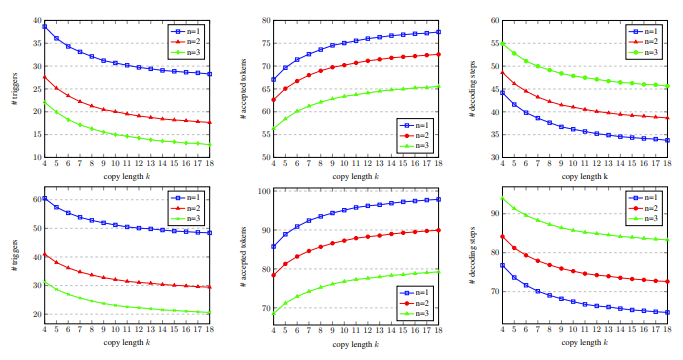


-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。












