
- 0
- 0
- 0
分享
- Hold住千亿参数大模型,Gaudi®2 有何优势
-
2023-09-15
近日在北京举行的2023年中国国际服务贸易交易会(下文简称:服贸会)上,作为英特尔人工智能产品组合的重要成员,Habana® Gaudi®2实力亮相,它在海内外诸多大语言模型(Large Language Model,下文简称:LLM)的加速上,已展现了出众实力,成为业界焦点。

专为加速LLM的训练和推理设计

在千亿参数大模型上大显身手
数据显示,Habana® Gaudi®2在GPT-J-99 和GPT-J-99.9 上的服务器查询和离线样本的推理性能分别为78.58 次/秒和84.08 次/秒。该测试采用 FP8数据类型,并在这种新数据类型上达到了 99.9% 的准确率,这无疑再一次印证了Gaudi®2的出色性能。此外,基于第四代英特尔®至强®可扩展处理器的7个推理基准测试也显示出其对于通用AI工作负载的出色性能。截至目前,英特尔仍是唯一一家使用行业标准的深度学习生态系统软件提交公开CPU结果的厂商。

图 1. BLOOMZ 在 Gaudi®2 和第一代 Gaudi® 上的推理时延测试结果
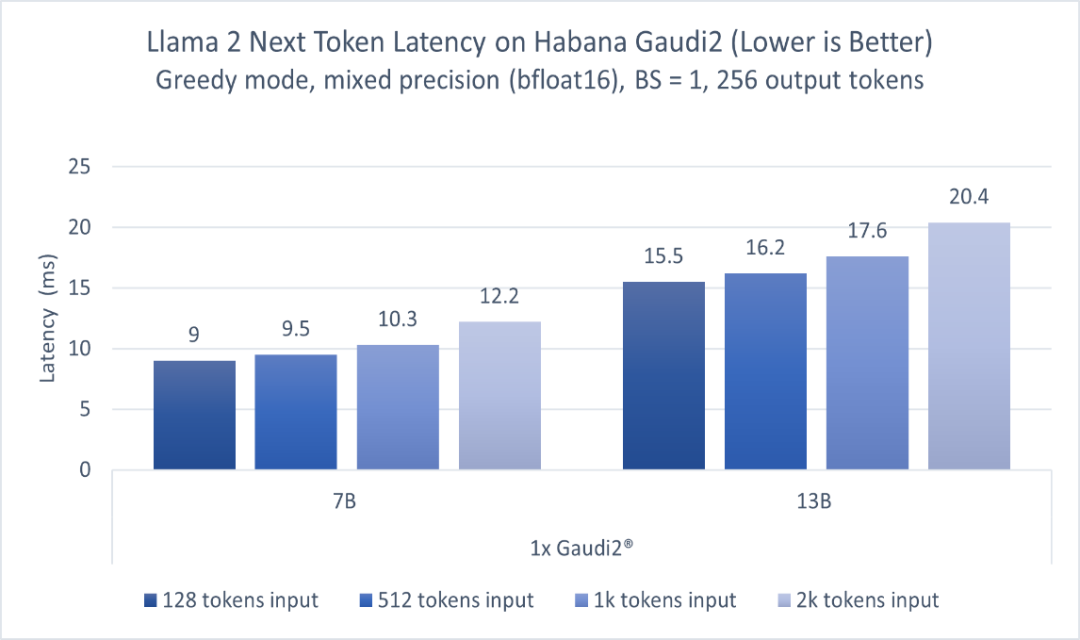
图 2. 基于Habana® Gaudi®2,70亿和130亿参数Llama 2模型的推理性能
值得一提的是,Habana 的SynapseAI® 软件套件在模型部署和优化的过程中起到了至关重要的作用。SynapseAI® 软件套件不仅支持使用 PyTorch 和 DeepSpeed 来加速LLM的训练和推理,还支持 HPU Graph和DeepSpeed-inference,这两者都非常适合时延敏感型应用。因此,在Habana® Gaudi®2上部署模型非常简单,尤其是对LLM等数十亿以上参数的模型推理具有较优的速度优势,且无需编写复杂的脚本。
LLM的成功堪称史无前例。有人说,LLM让AI技术朝着通用人工智能(AGI)的方向迈进了一大步,而因此面临的算力挑战也催生了更多技术的创新。Habana® Gaudi®2 正是在这一背景下应运而生,以其强大的性能和性价比优势加速深度学习工作负载。Habana® Gaudi®2的出色表现更进一步显示了英特尔AI产品组合的竞争优势,以及英特尔对加速从云到网络到边缘再到端的工作负载中大规模部署AI的承诺。英特尔将持续引领产品技术创新,丰富和优化包括英特尔® 至强® 可扩展处理器、英特尔® 数据中心GPU等在内的AI产品组合,助力中国本地AI市场发展。
参考资料:
1.https://huggingface.co/blog/zh/habana-gaudi-2-bloom
2.Habana® Gaudi®2深度学习加速器:所有测量使用了一台HLS2 Gaudi®2服务器上的Habana SynapseAI 1.10版和optimum-habana 1.6版,该服务器具有八个Habana Gaudi®2 HL-225H Mezzanine卡和两个英特尔® 至强® 白金8380 CPU@2.30GHz以及1TB系统内存。2023年7月进行测量。

-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “英特尔中国” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
-

-
北京
甲方 · 品牌主
未认证的机构号
最近发布
-
2023-09-15
-
2023-09-15












