
- 0
- 0
- 0
分享
- 优化实践系列教程 | 渲染优化
-
原创 2022-05-11
本文是优化实践系列教程的第二篇,更多教程欢迎点击合集学习。
对于 3D 实时应用来说,渲染模块涉及面广,包括场景,角色,光照,特效以及后处理等系统都需要渲染模块的支持,因此,该模块的优化是大多数项目在性能优化时的重点和难点。从上一次的 UPR 性能分析结果看,渲染同样是占用最多时间的模块

寻找性能热点
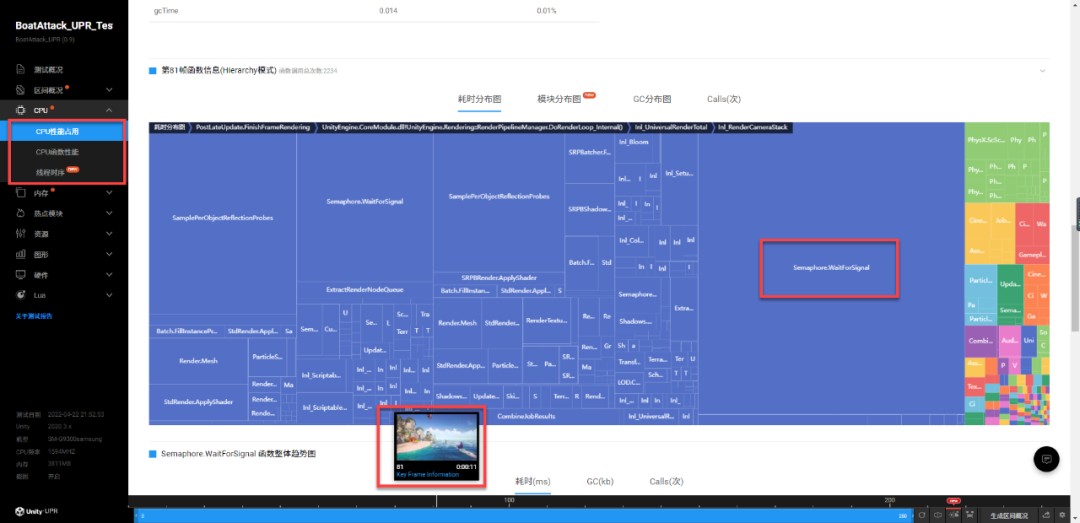
要对性能进行优化,首先就是找到每一帧中最耗时的函数(也称之为性能热点),然后对其进行优化。从 UPR 提供的模块耗时分布图中,我们可以较为容易找到性能热点。比如在当前这一帧的耗时分布图中,我们看到其中有一个函数 Semaphore.WaitForSignal 耗时较大,我们可以先对其进行分析。
判断性能瓶颈是 CPU-Bound 还是 GPU-Bound
Semaphore.WaitForSignal 表示在等待另一个线程,所以导致问题的原因可能是在另一个线程上,可以使用线程时序视图查看其他线程并行发生的情况,如下图所示。

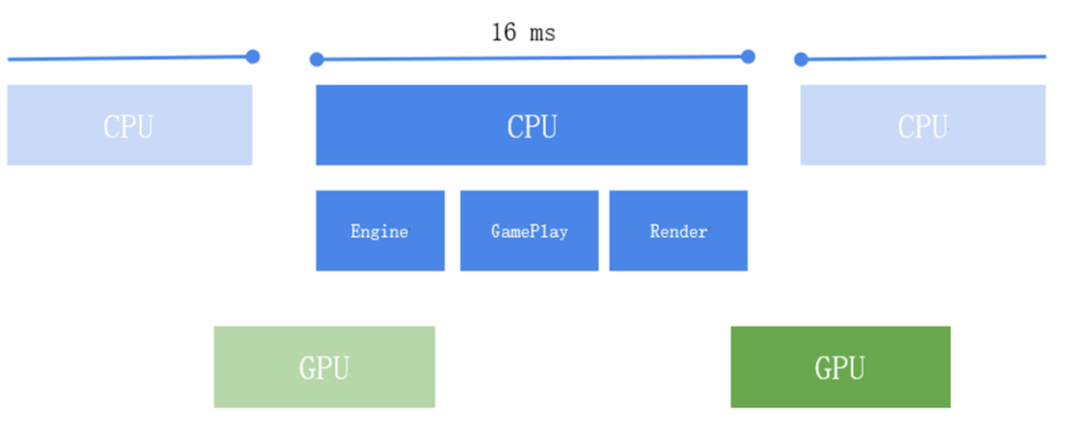
通过时序图,我们可以确定问题是属于 CPU Bound 还是GPU Bound。关于这个问题,我们稍微做下解释。正常情况下,CPU 在计划的帧时内完成相关工作,并将准备好的绘制数据提交给 GPU 执行,如下图所示:
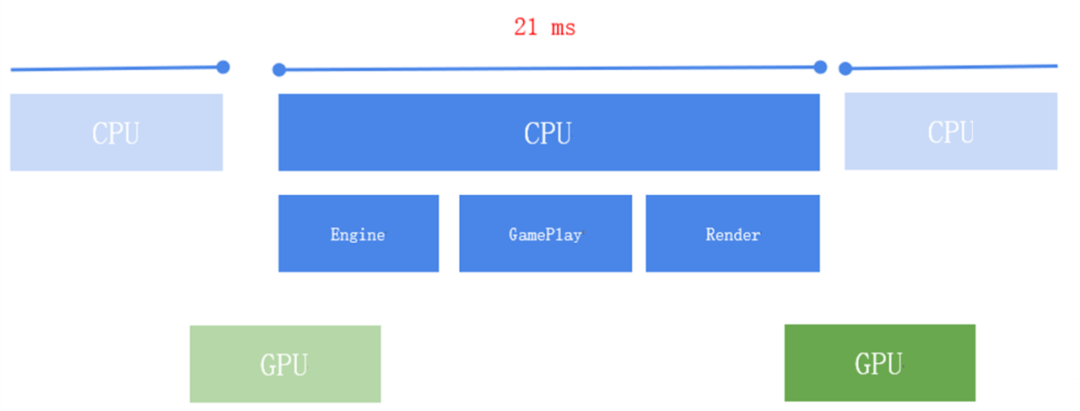
但有时候可能计算量比较大,会导致超过计划的帧时,这种情况我们称之为 CPU-bound,如下图所示。
与上一种情况相反,当 GPU 执行时间过长,导致 CPU 需要等待 GPU 完成任务时,我们称之为 GPU-bound 的性能问题。
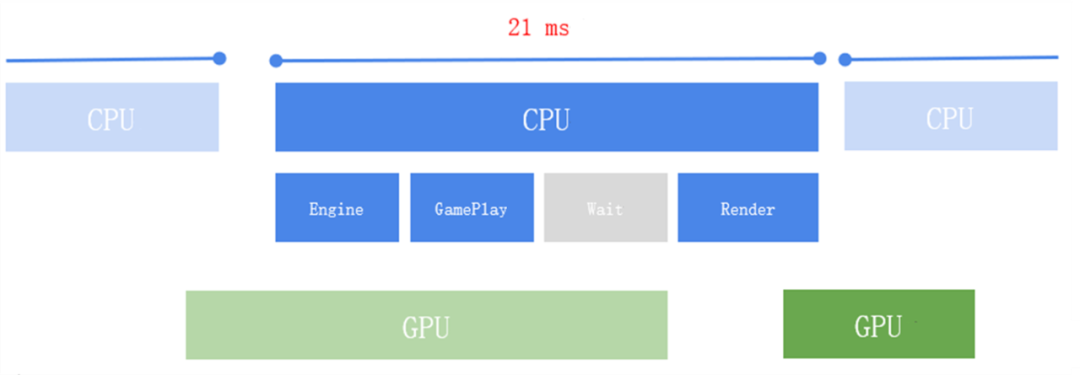
如果 CPU 导致的性能问题,我们可以继续分析渲染模块的函数栈,找出热点函数,进一步诊断问题的原因。
对渲染模块的热点函数进行分析
在模块分布图中点击 Rendering 模块,可以看到渲染相关的热点函数,如下图所示:
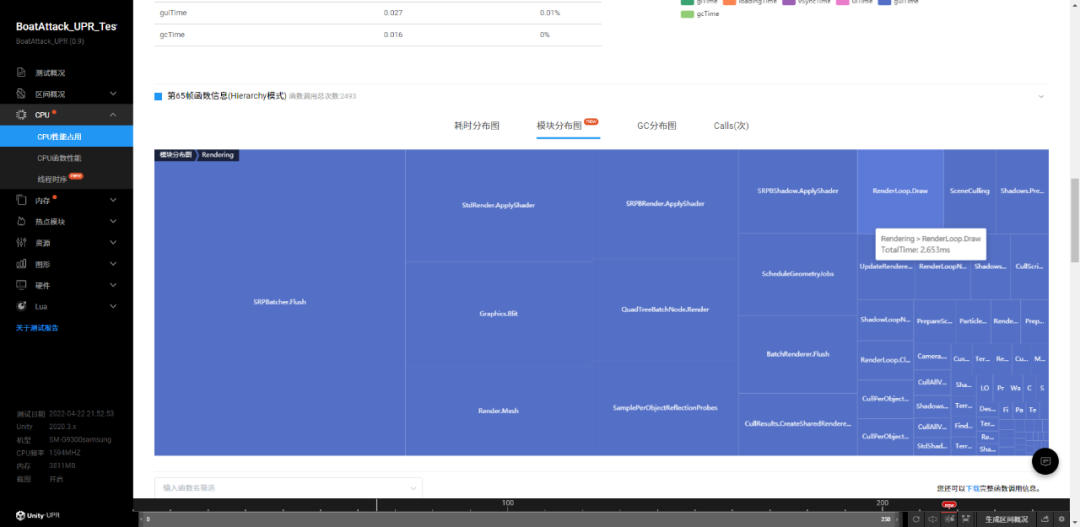
点击感兴趣的函数,可以在函数调用栈中找到该函数的调用关系。以 SRPBatcher.Flush 函数为例,我们可以看到所有对应的调用栈。
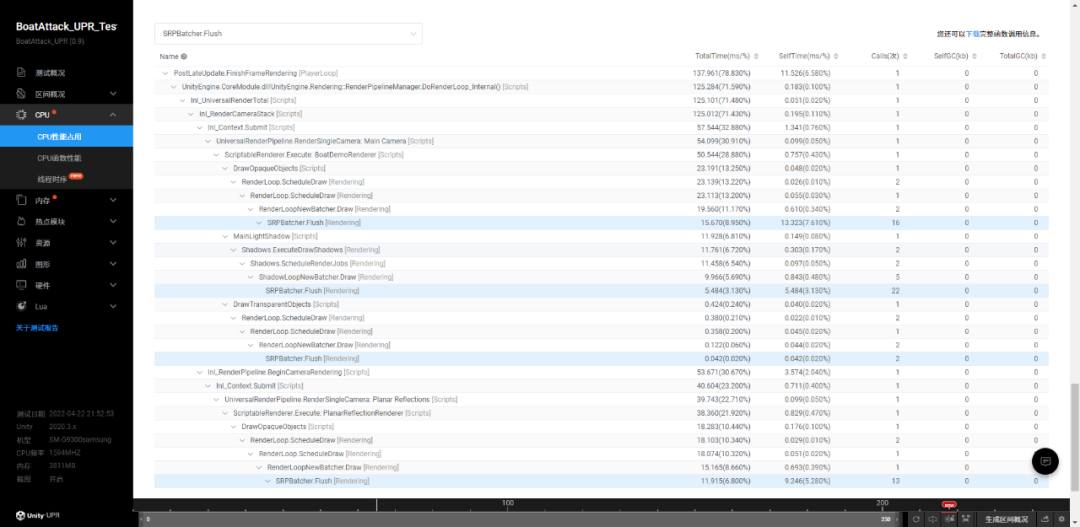
SRPBatcher.Flush 表示提交 Draw Calls。从上面到调用中,我们看到它主要被主 Camera 和镜面反射的相机所调用。其中镜面反射部分也有不少消耗,在低端设备中可以考虑去掉镜面反射的显示。主相机的耗时可以考虑减少 Mesh,Culling,合批等手段进一步减少 DrawCalls。
除此以外,我们还看到 SamplePerObjectRefectionProbes,QuadTreeBatchNode.Render,ScheduleGeometryJobs 等热点函数,分别和反射,地形及粒子等系统相关,可以对这些系统进行进一步分析和优化。当然,如果想了解更多函数的意义可以参考手册 Profiler Markers。
优化Draw Call
通过 UPR 初步诊断后,可以进一步用 Frame Debugger 对场景中的绘制情况进行分析,查看是否有多余的绘制调用(Draw call),或者没有正确合批(Batching)的绘制调用,从而减少渲染部分的开销。
揭秘 Draw call
游戏中的每一帧,Unity 都会确定需要渲染哪些对象,然后,创建绘制调用。绘制调用是对图形 API 的调用以绘制对象,如下图所示。
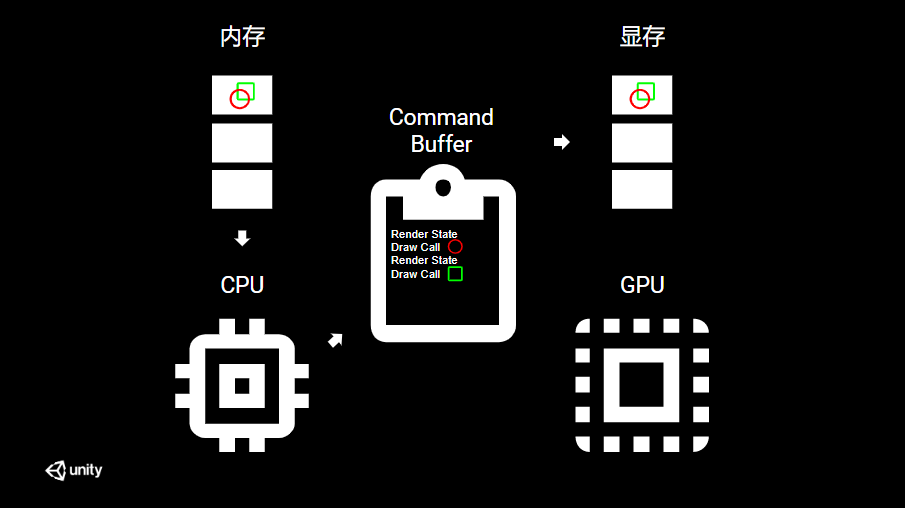
通常,当我们讨论图形优化时,会谈论如何减少 Draw call,但更准确地说是减少 Render State。Render State 是一组设置,例如顶点着色器,像素着色器,纹理和光照设置。每当 Render State 发生变化时,都会发出一个 SET PASS CALL, 也就是在 Stat 窗口中列出的 SetPassCall。例如,场景中的球体网格具有红色材质,而另一个球体网格具有蓝色材质。因为这两个球体不共享相同的渲染状态设置(顶点着色器、像素着色器、纹理、照明设置),所以将两个渲染状态提供给命令缓冲区。
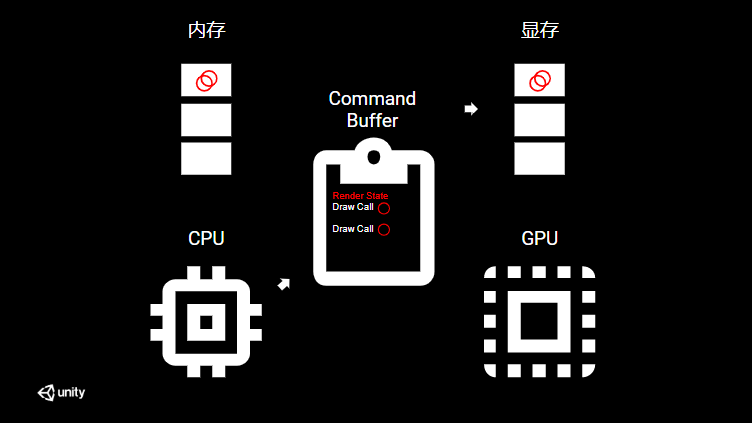
由于 Render State 比 Draw call 更昂贵,我们需要减少 Render State 或 SetPass 调用的数量,将具有相同 Render State 的 Draw call 合并在一起进行绘制,也就是所谓的合批 (Batching),如下图所示。
利用 Frame Debugger 分析场景 Draw call
使用 Frame Debugger 对《Boat Attack》项目进行 Draw call分析,如下图所示:
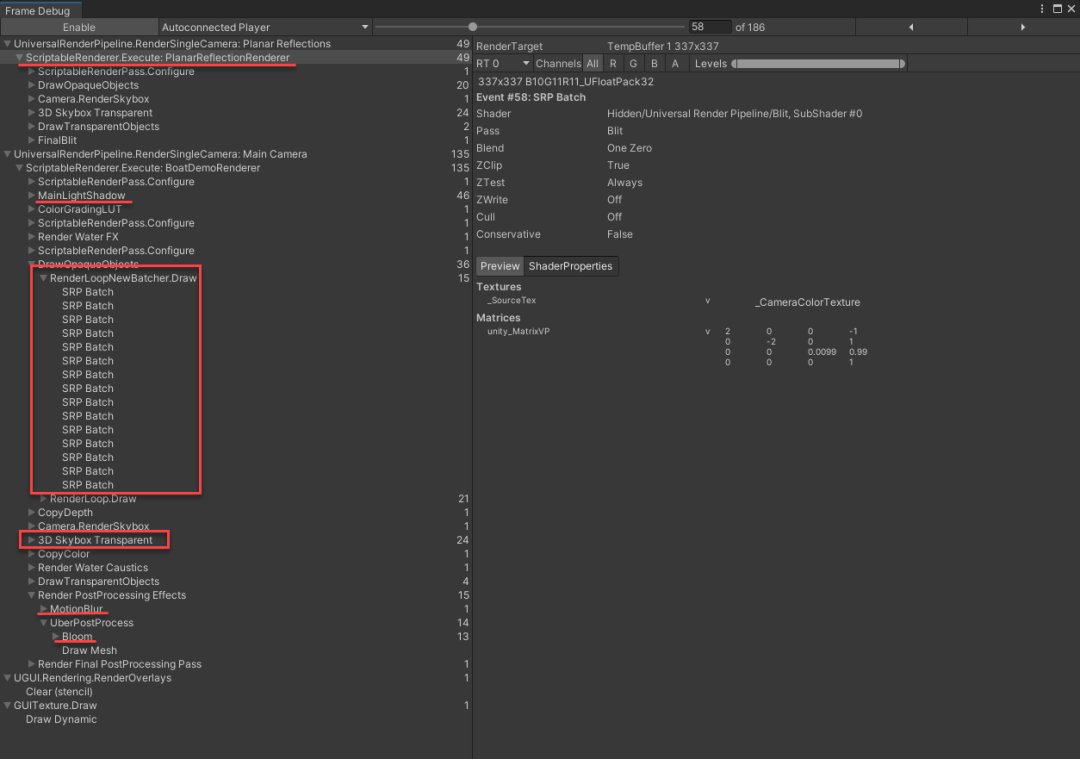

通过查看整个场景的绘制调用,我们可以清晰得了解到场景的绘制过程。虽然场景物体较多,但大多数不透明物体的绘制,系统成功使用了 SRP Batcher 进行了合批。另外,也有部分占用绘制调用较多的地方,有进一步优化的空间,比如:
 场景中使用了一个相机来实现水面镜面反射的效果; 天空盒使用了半透明的渲染方式,占用了不少 Draw call; 使用了 Motion Blur 和 Bloom 等开销较大的后处理;
场景中使用了一个相机来实现水面镜面反射的效果; 天空盒使用了半透明的渲染方式,占用了不少 Draw call; 使用了 Motion Blur 和 Bloom 等开销较大的后处理; 场景中大量物体使用了实时阴影。
目前 Unity 支持的合批方式主要包含如下 4 种:
Dynamic Batching,对于小网格,Unity 可以分组和变换 CPU 上的顶点,然后一次性将它们全部绘制出来。详细用法可以参考手册 Dynamic Batching;
https://docs.unity3d.com/Manual/static-batching.html
Static Batching,对于不移动的几何体,Unity 可以减少共享相同的材质的网格的 Draw call。详细用法可以参考手册 Static Batching;
https://docs.unity3d.com/Manual/static-batching.html
GPU Instance,基于图形硬件提供的支持,将大量相同的对象一次性绘制出来。详细用法可以参考手册 GPU Instance;
https://docs.unity3d.com/Manual/GPUInstancing.html
SRP Batcher,URP 渲染管线专有的合批方式,详细用法可以参考 SRP Batcher。
https://docs.unity3d.com/Manual/SRPBatcher.html
优化GPU相关性能瓶颈
除了直接对绘制调用次数进行优化外,直接对绘制调用本身进行优化也是需要考虑的因素,也就是直接对 GPU 上的计算本身进行优化。影响 GPU 性能三大因素:填充率、顶点运算、内存带宽,及其诊断方式如下图所示:

其中 OverDraw,Shader 性能等指标可以通过 Render Doc,Xcode Instruments 等工具进行分析。
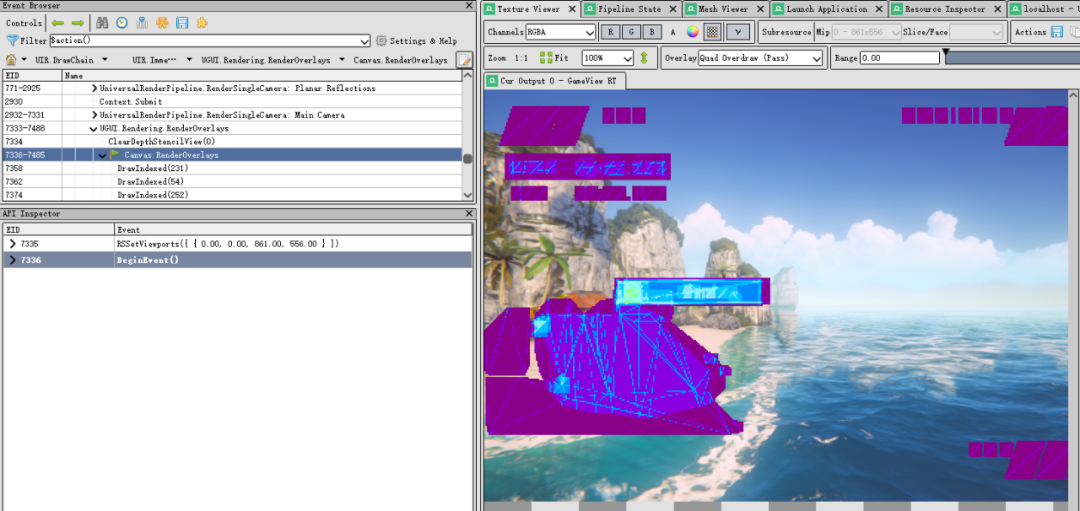
在Render Doc中查看每一个Draw call的Overdraw情况
以上就是关于图形优化的基本流程和方法的介绍。
简而言之,先通过 UPR 或者 Profiler 确定是 CPU-bound 还是 GPU-bound 的性能问题,如果是 CPU-bound 的,我们可以对热点函数和 Draw call 进行优化;如果是 GPU-bound 的问题,则可以考虑对顶点数,纹理分辨率,Shader 复杂度以及 Overdraw 等因素进行优化。
当然,正如前言所说,虽然整体流程如此,但由于涉及到光照,地形,角色,特效,UI,以及后处理等众多模块,且每个项目各有侧重取舍,所以渲染部分的优化方法没有万能解,还是需要针对项目特点,制定适合自身项目特点的优化方案。后续我们也仍然会继续对优化工具及优化案例进行讲解,希望能够为实际项目提供借鉴和参考。
长按关注
第一时间了解Unity引擎动向,学习最新开发技巧

-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本内容由数艺网主动采集收录,信息来源为 “Unity官方平台” 公开网络发布内容。第三方如需转载本内容,必须完整标注原作者信息及 “来源:数艺网”,严禁擅自篡改、删减或未标注来源转载。 并附上本页链接: 若您的内容不希望被数艺网收录,或认为此举侵犯了您的合法权益,敬请通过微信 ID:d-arts-cn 联系数艺网。我们将致以诚挚歉意,并第一时间为您办理下架或删除处理。
-

-
上海
甲方 · 软件商
未认证的机构号
最近发布
-
2024-12-03
-
2024-02-27












